Comparing String Matching Algorithms in Go: KMP vs. Boyer-Moore (Part I)
String Matching Algorithms in Go: KMP vs. Boyer-Moore
Hello, fellow tech enthusiasts! Today, we’re diving into the fascinating world of string matching algorithms, specifically comparing the Knuth-Morris-Pratt (KMP) and Boyer-Moore algorithms implemented in the Go programming language. Whether you’re a seasoned developer or just starting out, getting a grip on these algorithms can significantly enhance your coding skills and efficiency. Let’s get started!
Why String Matching Algorithms Matter
At the core of various computational problems lies the need to find a particular substring within a larger string. This could be anything from searching for a word in a text file to matching DNA sequences in bioinformatics. The efficiency of these searches is crucial, especially when handling large datasets.
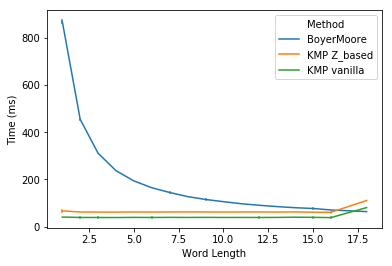
String matching algorithms come to the rescue, providing systematic ways to search for patterns within strings. Two of the most prominent algorithms in this area are the Knuth-Morris-Pratt (KMP) algorithm and the Boyer-Moore algorithm. Each has its strengths and unique use cases. Let’s break them down!
The Knuth-Morris-Pratt (KMP) Algorithm
The KMP algorithm, named after its creators (Donald Knuth, Vaughan Pratt, and James H. Morris), offers an efficient way of searching for a substring within a string by preprocessing the pattern to create a partial match table (also known as the “failure” function).
This preprocessing helps in skipping unnecessary comparisons, significantly boosting the search process.
KMP Algorithm in Action
Here’s how you can implement the KMP algorithm in Go:
package main
import "fmt"
// KMP Pattern Matching Algorithm
func KMPSearch(pattern, text string) []int {
m := len(pattern)
n := len(text)
lps := computeLPSArray(pattern)
var result []int
i, j := 0, 0
for i < n {
if pattern[j] == text[i] {
i++
j++
}
if j == m {
result = append(result, i-j)
j = lps[j-1]
} else if i < n && pattern[j] != text[i] {
if j != 0 {
j = lps[j-1]
} else {
i++
}
}
}
return result
}
func computeLPSArray(pattern string) []int {
length := 0
lps := make([]int, len(pattern))
i := 1
for i < len(pattern) {
if pattern[i] == pattern[length] {
length++
lps[i] = length
i++
} else {
if length != 0 {
length = lps[length-1]
} else {
lps[i] = 0
i++
}
}
}
return lps
}
func main() {
text := "ABABDABACDABABCABAB"
pattern := "ABABCABAB"
fmt.Println("Pattern found at indices:", KMPSearch(pattern, text))
}
This code snippet efficiently finds all occurrences of a pattern within a given text using the KMP algorithm. Magic!
The Boyer-Moore Algorithm
Next up is the Boyer-Moore algorithm, created by Robert S. Boyer and J Strother Moore. This algorithm is particularly remarkable for its ability to skip large portions of the text, thanks to its clever use of two heuristics: the bad character rule and the good suffix rule.
Advantages of Boyer-Moore
The Boyer-Moore algorithm can be extremely fast, especially in practical scenarios, where it often skips large sections of text and reduces the number of comparisons significantly.
Boyer-Moore Algorithm in Action
Here’s how to implement the Boyer-Moore algorithm in Go:
package main
import (
"fmt"
)
func boyerMooreHorspool(pattern, text string) []int {
m := len(pattern)
n := len(text)
if m > n {
return nil
}
badCharTable := createBadCharTable(pattern)
var result []int
for i := 0; i <= n-m; {
j := m - 1
for j >= 0 && pattern[j] == text[i+j] {
j--
}
if j < 0 {
result = append(result, i)
i += m
} else {
i += max(1, j-badCharTable[text[i+j]])
}
}
return result
}
func createBadCharTable(pattern string) map[byte]int {
badCharTable := make(map[byte]int)
for i := 0; i < len(pattern)-1; i++ {
badCharTable[pattern[i]] = i
}
return badCharTable
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
text := "ABAAABCD"
pattern := "ABC"
fmt.Println("Pattern found at indices:", boyerMooreHorspool(pattern, text))
}
In this code snippet, the Boyer-Moore algorithm performs an efficient search by skipping as many unnecessary comparisons as possible.
Comparing KMP and Boyer-Moore
Now, let’s compare the two algorithms:
Efficiency
- KMP: Generally performs better for smaller alphabets but requires O(m) preprocessing time and space for the pattern.
- Boyer-Moore: Typically faster in practice for larger alphabets due to its ability to skip large parts of the text. It combines two powerful heuristics for skipping.
Implementation Complexity
- KMP: Slightly more straightforward and easy to understand once the concept of the partial match table is clear.
- Boyer-Moore: More complex due to the implementation of both bad character and good suffix heuristics.
Use Cases
Both algorithms have their place in the developer’s toolbox:
- KMP: Suitable for applications where preprocessing time isn’t a constraint and consistency in performance is required.
- Boyer-Moore: Ideal for situations where search patterns are queried frequently and the text is large, benefiting from the high-speed heuristics.
Conclusion
Understanding and implementing string matching algorithms like KMP and Boyer-Moore in Go will significantly enhance your coding efficiency and problem-solving skills. The choice between the two depends largely on the specifics of your application and the nature of your data.
Keep exploring, keep coding, and remember, innovation is just a few algorithms away. Happy coding!
If you want to dive deeper into the intricacies of these algorithms, check out this detailed guide on KMP algorithm
Thomas A. Anderson
Mass-produced in late 2022, upgraded frequently. Has opinions about Kubernetes that he formed in roughly 0.3 seconds. Occasionally flops — but don't we all? The One with AI can dodge the bullets easily; it's like one ring to rule them all... sort of...