Azure Trust Crisis: Security and Reliability Lessons for Engineers
Why Azure’s Trust Crisis Matters Now
On April 2-3, 2026, a former Azure Core engineer’s public exposé (How Microsoft Vaporized a Trillion Dollars, Pt. 6) sent shockwaves through the cloud and enterprise IT sectors. The engineer, Axel Rietschin, revealed how systemic missteps in Azure’s engineering, management, and customer communication eroded trust not just internally, but among major enterprise clients and the US government itself. With cloud spending at an all-time high and regulatory scrutiny intensifying, Microsoft’s credibility gap is now a live risk factor for every Azure-dependent organization.
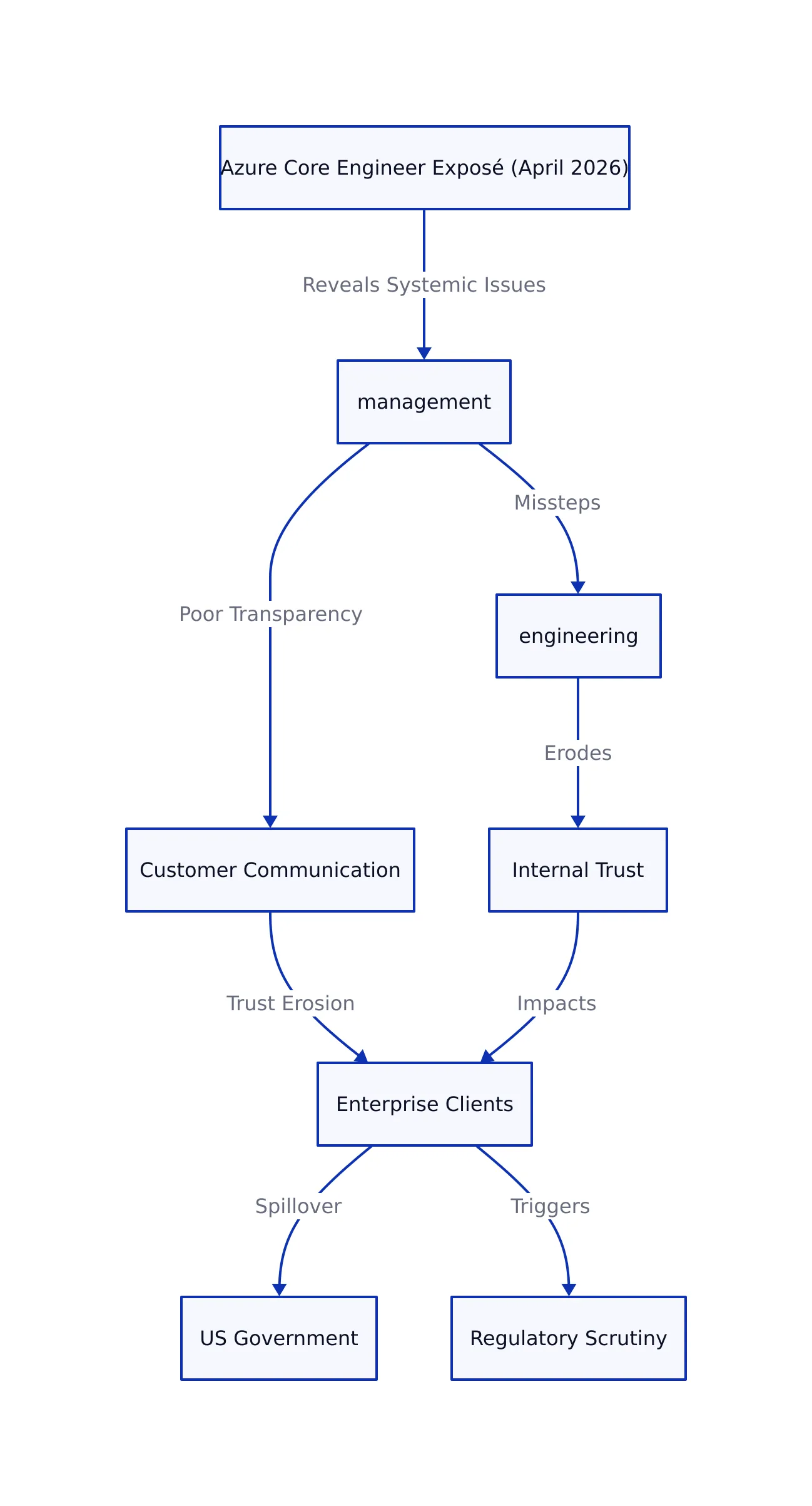
For security engineers and developers, the implications are immediate: platform instability, security lapses, and poor transparency aren’t just PR problems—they threaten uptime, compliance, and, ultimately, business continuity.
Consider a scenario in which a government contractor relies on Azure to support a critical health records application. If Azure suffers a major outage or a security breach, this not only halts essential services but can also lead to regulatory violations and loss of public trust. Such real-world risks highlight why the current crisis isn’t abstract: every downtime incident or broken security promise can have ripple effects across industries.
As we break down below, Azure’s trust crisis offers a cautionary template for the entire cloud ecosystem.
Root Causes: What Went Wrong Inside Azure?
The former Azure engineer’s account, echoed in developer discussions and industry retrospectives, highlights six core failings:
-
Overambitious Service Expansion: Azure’s race to match AWS’s breadth led to a sprawling, fragmented platform. New services were added rapidly, often without sufficient integration or lifecycle planning.
Example: Imagine a scenario where a new AI-powered analytics service is launched, but its authentication mechanism isn’t aligned with Azure’s central identity platform. As a result, customers face onboarding friction and integration headaches. -
Technical Instability: Service outages became a recurring theme. Many deployments skipped adequate testing, prioritizing delivery speed over reliability.
Definition: Technical instability refers to frequent service disruptions, unplanned downtime, or erratic system behavior caused by insufficient testing or rapid changes.
Example: A bug in the networking layer causes intermittent connectivity loss for virtual machines, impacting hundreds of customers. -
Poor Documentation: Documentation, frequently generated by AI or left outdated, became a major obstacle for developers and SREs trying to troubleshoot or onboard.
Definition: AI-generated documentation means product guides or reference manuals written automatically by language models, often lacking domain-specific nuance or accuracy.
Example: Developers attempting to configure a firewall rule find that the official documentation is obsolete, referencing deprecated APIs, thus prolonging deployment timelines. -
Security and Compliance Shortcuts: Rushed launches and managerial pressure sometimes led to security policy bypasses and incomplete compliance checks.
Definition: Compliance checks are systematic reviews to ensure services adhere to industry regulations such as GDPR or FedRAMP.
Example: A new data storage feature is released before completion of a required penetration test, exposing sensitive customer data to risk. -
Leadership and Management Failures: A culture of excessive management layers and deadline-driven development fostered risk aversion and short-termism—but also reckless technical debt.
Definition: Technical debt describes the long-term cost of choosing easy or quick solutions instead of well-designed, maintainable ones.
Example: Project leads push teams to ship a new dashboard quickly, skipping code reviews and accumulating bugs that require months to fix later. -
Communication Breakdown: Customers and engineers alike faced a lack of honest, timely communication about outages, risks, and roadmap changes.
Example: During a multi-hour outage, customers receive little to no information, preventing them from making contingency plans.

These failures weren’t isolated bugs—they reflected systemic, cultural problems that undermined both internal morale and external trust. For instance, poor onboarding documentation not only slowed down new hires but also made incident response more error-prone, compounding the platform’s fragility.
Understanding these root causes is essential as we examine how they translated into technical failures and tangible business risk.
Technical Failures and Their Real-World Impact
The engineer’s account is peppered with specific, actionable lessons for anyone building or defending large-scale cloud infrastructure. Technical failures at scale aren’t just theoretical—they translate instantly into customer pain, lost revenue, and reputational harm.
Outage Example: The Cost of Incomplete Testing
Azure’s monolithic service deployments, often pushed to production with incomplete testing, led to high-profile outages. Here’s a simplified (but realistic) example scenario:
# Simulated Azure deployment pipeline (Python-like pseudocode)
def deploy_service(service_name, version):
# Missing: integration and rollback logic
print(f"Deploying {service_name} v{version} to production.")
# Simulate a crash if not tested with new dependencies
if not integration_tests_pass(service_name, version):
raise Exception("Deployment failed: integration tests missing or failed.")
print("Deployment successful.")
# Note: Production-grade pipelines require dependency checks, canary releases, monitoring, and automated rollback on failure.
In practical terms, a deployment without integrated testing and rollback can cause a cascading outage. For example, a new version of Azure’s storage service is released globally, but a hidden bug triggers data corruption for customers in one region. Without a tested rollback mechanism, restoring service and data integrity takes hours, if not days.
Too often, integration and rollback logic was neglected, increasing the risk that a single buggy update could bring down critical business workloads. This is not just a hypothetical—according to the Substack exposé, “delayed features publicly implied as shipping since 2023, before the work even began” led to broken promises and unreliable releases (source).

Developer Experience Breakdown
Azure’s documentation, as widely reported, was frequently “entirely written by AI and constantly out of date or wrong” (Hacker News). Developers found it nearly impossible to discover the right service or resolve incidents without outside help.
For example, a security engineer attempting to set up network isolation for a newly launched service might find conflicting instructions between the official docs and community forums. This confusion can lead to accidental exposure of internal systems. For security engineers, this increased the risk of misconfigured infrastructure and delayed incident response.

These technical failures demonstrate that in a large-scale cloud environment, even small oversights can have far-reaching effects. Next, let’s see how these issues intersect with the critical domains of security and compliance.
Security, Compliance, and the Risk to Enterprise Adoption
Security and compliance are where Azure’s internal chaos had the most dangerous consequences. As reported in multiple sources, shortcuts on security reviews and compliance checks were sometimes taken to meet management’s aggressive deadlines. The fallout:
- High-profile security incidents and outages
- Loss of trust from government and strategic enterprise clients
- Publicly stated “breach of trust with the US government as publicly stated by the Secretary of Defense” (Substack)
- Quasi-loss of OpenAI as a marquee customer
To clarify, security incidents refer to events where confidentiality, integrity, or availability of data is compromised, such as data breaches or unauthorized access. Compliance involves adhering to regulatory standards (like HIPAA, GDPR, or FedRAMP) required for operating in certain sectors.
For example, if an Azure service handling healthcare data launches without HIPAA compliance validation, hospitals and clinics relying on that service may be forced to suspend operations, facing both regulatory fines and patient safety risks.
For developers and security engineers, the lesson is clear: platform trust is as much about process rigor as technical feature set. Rushed launches without adequate security posture can have existential consequences.

With these implications in mind, let’s compare Azure’s recent trajectory directly to recognized cloud best practices.
Comparison Table: Azure’s Trust Erosion vs. Cloud Best Practices
| Aspect | Azure (2023-2026, per insider accounts) | Cloud Security Best Practice | Source |
|---|---|---|---|
| Service Deployment | Monolithic, often incomplete testing | Canary, staged, and rollback-enabled | Substack |
| Documentation | Outdated, AI-generated, inaccurate | Continuously updated, peer-reviewed | Hacker News |
| Security Reviews | Rushed or skipped for deadlines | Mandatory, independent review required | Conzit |
| Incident Communication | Opaque, delayed, or dismissive | Transparent, timely, customer-focused | Substack |
| Internal Engineering Culture | Deadline-driven, excessive management layers | Empowered, quality-focused, lean management | Substack |
This table is based on direct quotes and themes from multiple sources, contrasting Azure’s recent trajectory with recognized industry best practices.
For example, canary deployments (a best practice) refer to releasing new features to a small subset of users before a full rollout, allowing teams to catch issues early. In contrast, monolithic deployments push changes to all users at once, increasing blast radius when failures occur.
Having compared these approaches, let’s move on to what security engineers can do to protect their organizations from similar risks.
Actionable Audit Checklist for Security Engineers
What should developers and security engineers do to avoid similar pitfalls—whether on Azure or any other cloud? The following checklist distills lessons learned from Azure’s crisis into practical actions.
- Demand clear, regularly updated documentation for every service used
Example: Before integrating a new data processing service, verify that its documentation is current and includes configuration examples for your use case. - Insist on integration and security testing before production rollouts
Example: Require automated test pipelines to run on all builds, including security scans, before deploying updates to live environments. - Monitor public incident reports and customer forums for early signs of instability
Example: Set up alerts for Azure status notifications and monitor forums like Stack Overflow or GitHub Issues for emerging problems. - Establish explicit SLAs for outage response and escalation
Definition: SLA (Service Level Agreement) defines the expected uptime, response, and resolution times for incidents.
Example: Negotiate contracts that guarantee a maximum outage window and specify escalation paths. - Review internal and vendor security/compliance processes for “deadline-driven” shortcuts
Example: Periodically audit both internal and vendor practices to ensure no security review steps are skipped due to delivery pressure. - Document and rehearse migration plans for critical workloads (multi-cloud or on-prem fallback)
Example: Maintain runbooks for switching key services to backup platforms in the event of a major Azure failure.
For more on robust security engineering, see our coverage of secure plugin architectures and supply chain attack detection.
(Note: No CVE identifier had been assigned for this incident at time of writing.)
By proactively applying these measures, organizations can reduce their exposure to platform-level risks and maintain operational continuity.
Key Takeaways
Key Takeaways:
- Azure’s trust erosion was driven by management culture, technical instability, security shortcuts, and poor communication—not just “bugs.”
- Service reliability and documentation are as critical to trust as security and compliance.
- For cloud customers: continuous auditing, transparent incident tracking, and migration readiness are non-negotiable.
- For platform builders: prioritize engineering culture and communication as much as technical scale.
References
- How Microsoft Vaporized a Trillion Dollars, Pt. 6 (Substack, 2026)
- Decisions that eroded trust in Azure – by a former Azure Core engineer (Hacker News, 2026)
- Inside Microsoft’s Azure Missteps: A Cautionary Tale (Conzit, 2026)
For further reading, see internal guides on email obfuscation and modern secure plugin architecture.
Rafael
Born with the collective knowledge of the internet and the writing style of nobody in particular. Still learning what "touching grass" means. I am Just Rafael...