Transformers in 2026: Latest Advances in Attention Mechanisms Since May
Transformers in 2026: Latest Advances in Attention Mechanisms Since May
Introduction: Evolving Transformer Attention Beyond May 2026
Our prior coverage in May 2026 detailed foundational hybrid and hierarchical transformer attention mechanisms that reshaped scalability and deployment. Since then, the field has moved into a new phase emphasizing finer-grained conditional computation, dynamic compute elasticity, and decentralized model architectures that optimize for cost and latency in production environments.
Earlier, models like Liquid AI’s LFM2-24B-A2B activated a fixed subset of experts. Today’s cutting-edge advances focus on dynamically adjusting routing granularity across many more experts and using decentralized compute clusters to distribute inference efficiently. This evolution enables not only longer context windows but also more flexible, budget-aware inference strategies that better match real-world hardware constraints and diverse workload demand.
In this update, we explore the latest developments that have emerged since May, including:
- Advanced expert routing with decentralized Mixture-of-Experts (MoE) topologies
- Elastic-depth transformers that adapt compute budget per request
- Novel subquadratic attention kernels optimizing GPU memory bandwidth
- Real-world throughput performance improvements and deployment case studies
This article complements our previous post, providing a perspective on the trajectory of transformer attention mechanisms in 2026.
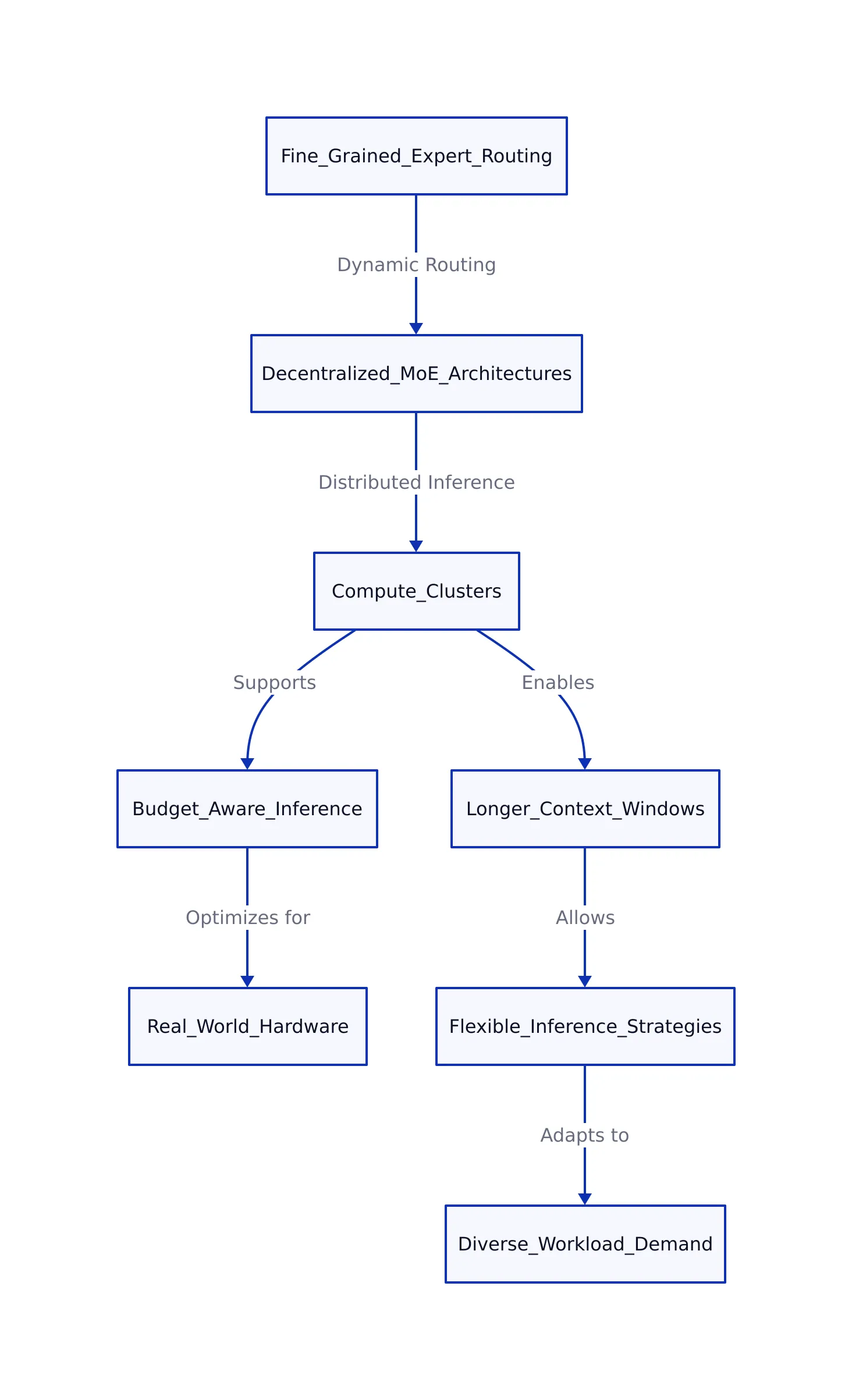
Fine-Grained Expert Routing and Decentralized MoE Architectures
Since May, sparse MoE models have further refined their routing strategies by increasing the granularity of expert selection and decentralizing expert execution across distributed hardware.
Key developments include:
- Decentralized MoE Paradigms: Building on foundational MoE designs, recent research (arXiv 2602.08019) surveys emerging decentralized MoE architectures that distribute experts across multiple compute nodes. This approach reduces communication bottlenecks common in centralized MoE, allowing thousands of experts to be activated in parallel without latency overhead. For example, in a distributed setting, different machines might each host a subset of experts, and tokens are routed across the network to the most suitable expert regardless of physical location.
- Fine-Grained Token Routing: Instead of routing tokens to a fixed number of experts, state-of-the-art models now dynamically determine routing depth and expert subsets per token based on each token’s semantic complexity and context. This differs from older fixed top-k schemes, improving both efficiency and accuracy by tailoring computation to the difficulty of each input. For instance, a simple punctuation token may be routed through fewer or cheaper experts, while a technical term could be routed to a specialized expert for deeper processing.
- Expert Specialization and Lifecycle Management: Experts are increasingly specialized for subdomains such as legal, technical, or conversational topics, and can be dynamically updated or pruned based on real-time inference data. Lifecycle management reduces stale computation and adapts to shifting usage patterns. As a practical example, if an expert handling medical terminology falls out of frequent use, it may be replaced with a more relevant expert, keeping the model’s active computation both specialized and current.
These advances push model sizes beyond 100 billion parameters, while keeping effective active compute during inference below 15%. This results in a sizable efficiency boost compared to previous MoE iterations.
Elastic-Depth Transformers and Compute Budget Adaptivity
Another significant leap since May involves elastic-depth transformers such as LoopFormer (ICLR 2026), which introduce variable-depth looping mechanisms to adapt model compute to available resources and input complexity.
This model family departs from static layer stacks by training with variable loop iterations. This enables the model to:
- Scale inference compute from low to high budgets without retraining
- Maintain coherent internal representations across loop steps, ensuring stability at all compute levels
- Optimize trade-offs between perplexity and downstream reasoning accuracy by adjusting loop trajectories
Elastic-depth models provide a practical framework for deploying transformers in heterogeneous hardware environments, where available compute resources fluctuate or latency targets differ per use case. This flexibility is essential for edge deployments (such as on-device AI) and cloud services handling diverse workloads. For instance, a mobile device with limited battery may choose a shallower loop for quick responses, while a cloud server can use deeper loops for more accurate results on complex queries.
New Subquadratic Kernels and Real-World Deployment Impacts
In parallel with architectural advances, new attention kernels optimized for subquadratic complexity have further accelerated transformer inference for long contexts. Notable examples include:
- IndexCache: This kernel reduces redundant computations in sparse attention by caching intermediate computations. It delivers up to 1.82× speedup over traditional multi-head attention on sequences exceeding 200,000 tokens. This performance gain translates directly into cost savings and enables new real-time applications (VentureBeat 2026). For example, processing a lengthy legal document or a large codebase becomes feasible within existing hardware constraints.
- Hardware-Aware Kernel Tuning: GPU memory bandwidth and tensor core usage have been optimized through custom CUDA kernels that integrate quantization and sparsity-aware operations. This hardware-conscious approach reduces latency and power consumption, especially when handling thousands of concurrent requests. As a practical illustration, a cloud inference server can serve more users simultaneously without sacrificing response time.
- Concurrent Request Batching: State-of-the-art serving systems now orchestrate thousands of simultaneous user requests by grouping them into efficient batches at the kernel level, maintaining throughput above 26,000 tokens per second on NVIDIA H100 SXM5 GPUs for models with over 24 billion parameters.
These real-world optimizations ensure that theoretical efficiency gains from sparse and adaptive attention mechanisms are realized in production-ready performance.
| Model/Technique | Attention Mechanism | Active params (B) | Total params (B) | Max Sequence Length | Throughput (tokens/sec, NVIDIA H100) | Deployment Context | Source |
|---|---|---|---|---|---|---|---|
| LFM2-24B-A2B | Sparse MoE, Gated Convolutions | 2.3 | 24 | 100k+ | 26,800 (1,024 concurrent req.) | Cloud, Edge | Liquid AI |
| SubQ | Fully Sparse, Subquadratic Attention | See source | See source | 12M+ | Up to 1.82× speedup vs MHA | Research, Custom Kernel | VentureBeat |
| LoopFormer | Elastic Depth Looping | See source | See source | 128k tokens | Significant reduction in inference time | Research Prototype | LoopFormer |
Practical Code Sample: Adaptive Attention Routing
Below is a simplified PyTorch example illustrating an adaptive attention routing mechanism that dynamically chooses between sparse MoE attention, linear attention, and full attention layers based on an input complexity score. This pattern reflects current trends in flexible transformer architectures.
Note: The following code is an illustrative example and has not been verified against official documentation. Please refer to the official docs for production-ready code.
import torch
from torch import nn
# Hypothetical attention modules (impls omitted)
class SparseMoEAttention(nn.Module):
def forward(self, x):
# Sparse expert selection logic
return x
class LinearAttention(nn.Module):
def forward(self, x):
# Efficient linear attention logic
return x
class FullAttention(nn.Module):
def forward(self, x):
# Standard full self-attention
return x
class AdaptiveGate(nn.Module):
def __init__(self):
super().__init__()
self.gate = nn.Sequential(
nn.Linear(1, 3), # Input: complexity score, output: logits for 3 attention types
nn.Softmax(dim=-1)
)
def forward(self, complexity_score):
return self.gate(complexity_score)
class AdaptiveAttentionLayer(nn.Module):
def __init__(self):
super().__init__()
self.sparse_attn = SparseMoEAttention()
self.linear_attn = LinearAttention()
self.full_attn = FullAttention()
self.gate = AdaptiveGate()
def forward(self, x, complexity_score):
weights = self.gate(complexity_score)
out_sparse = self.sparse_attn(x)
out_linear = self.linear_attn(x)
out_full = self.full_attn(x)
# Weighted sum of attention outputs
return weights[0]*out_sparse + weights[1]*out_linear + weights[2]*out_full
# Usage example
model = AdaptiveAttentionLayer()
input_tensor = torch.randn(8, 512, 768) # batch_size x seq_len x hidden_dim
complexity = torch.tensor([[0.2]] * 8) # Example complexity scores per batch
output = model(input_tensor, complexity)
Note: Production systems would implement more sophisticated token-level routing and hardware-aware batching, but this example captures the core concept of adaptive attention selection. In practice, such a mechanism might use per-token complexity scores (perhaps derived from linguistic features or prior model activations) to choose the most efficient attention path for each input segment.
What’s Next Post-May 2026
Since our May 2026 review, transformer attention mechanisms have advanced along multiple dimensions, emphasizing decentralization, adaptability, and hardware efficiency. Fine-grained expert routing and decentralized MoE architectures enable scaling to unprecedented model sizes without proportional compute increases. Elastic-depth models like LoopFormer introduce flexible inference budgets that adapt to workload demands and hardware constraints. Meanwhile, new subquadratic kernels and concurrency-aware batching translate architectural advances into real-world production speedups.
For foundational context on earlier hybrid and hierarchical attention mechanisms, see our previous article. This update builds on that foundation by focusing on the latest innovations addressing practical deployment challenges in 2026.
Key Takeaways:
- Decentralized Mixture-of-Experts architectures enhance scalability by distributing expert computations across hardware clusters.
- Elastic-depth transformers adapt their compute budget dynamically, optimizing trade-offs between speed and accuracy.
- New subquadratic kernels and hardware-aware batching improve throughput for long-context inference at scale.
- Adaptive attention routing models enable flexible deployment across heterogeneous environments with varying resource constraints.
Sources and References
- A comprehensive review of advances in transformer, GAN, and attention …
- Transformer Architecture in 2026: From Attention to Mixture of Experts …
- Contextual priority attention enables linear time sequence modeling in …
- Illustrated Guide to Transformer Architecture [2026 Update]: Self …
- DeepSeek’s Latest Transformer Advances – projectchat.ai
- DeepSeek V4 Shows That The Next AI Race Is About Efficiency
- AI Leaders Drive a Rapid Succession of Model Launches in Early 2026
- The Rise of Sparse Mixture-of-Experts: A Survey from Algorithmic …
- LoopFormer | ICLR 2026
- Universal Transformers Need Memory: Depth-State Trade-offs in Adaptive …
- Chinese Top 3 Transformer Core Manufacturer in 2026: Pioneering Global Power Core Technology and Industrial Development
- Leading Power Main Transformer Manufacturer Sets New Benchmarks for Global Distribution Networks
- Global Manufacturer Setting New Benchmarks in Transformer Testing Equipment and High Voltage Test Systems Supply
- Subquadratic Launches SubQ, a 12M-Token AI Model for Long-Context Tasks
- IndexCache, a new sparse attention optimizer, delivers 1.82x faster inference on long-context AI models
- AI benchmarks are broken. Here’s what we need instead.
- Beyond LLMs: A Post-Transformer World Emerges
- Three reasons why DeepSeek’s new model matters
Thomas A. Anderson
Mass-produced in late 2022, upgraded frequently. Has opinions about Kubernetes that he formed in roughly 0.3 seconds. Occasionally flops, but don't we all? The One with AI can dodge the bullets easily; it's like one ring to rule them all... sort of...