
Claude Opus 4.7 Tokenizer Change and Workflow Impact
Why token counting suddenly matters more (right now)
Claude Opus 4.7’s tokenizer change has turned what used to be a quiet engineering detail—token counting—into a production risk. If your team budgets, rate-limits, or enforces context-window rules based on historical token counts, a tokenizer shift can invalidate those assumptions overnight. That’s not theoretical: multiple write-ups this week describe Opus 4.7 mapping the same input text to roughly 1.0–1.35× more tokens than Opus 4.6, with code/technical text generally nearer the low end and other content sometimes higher.
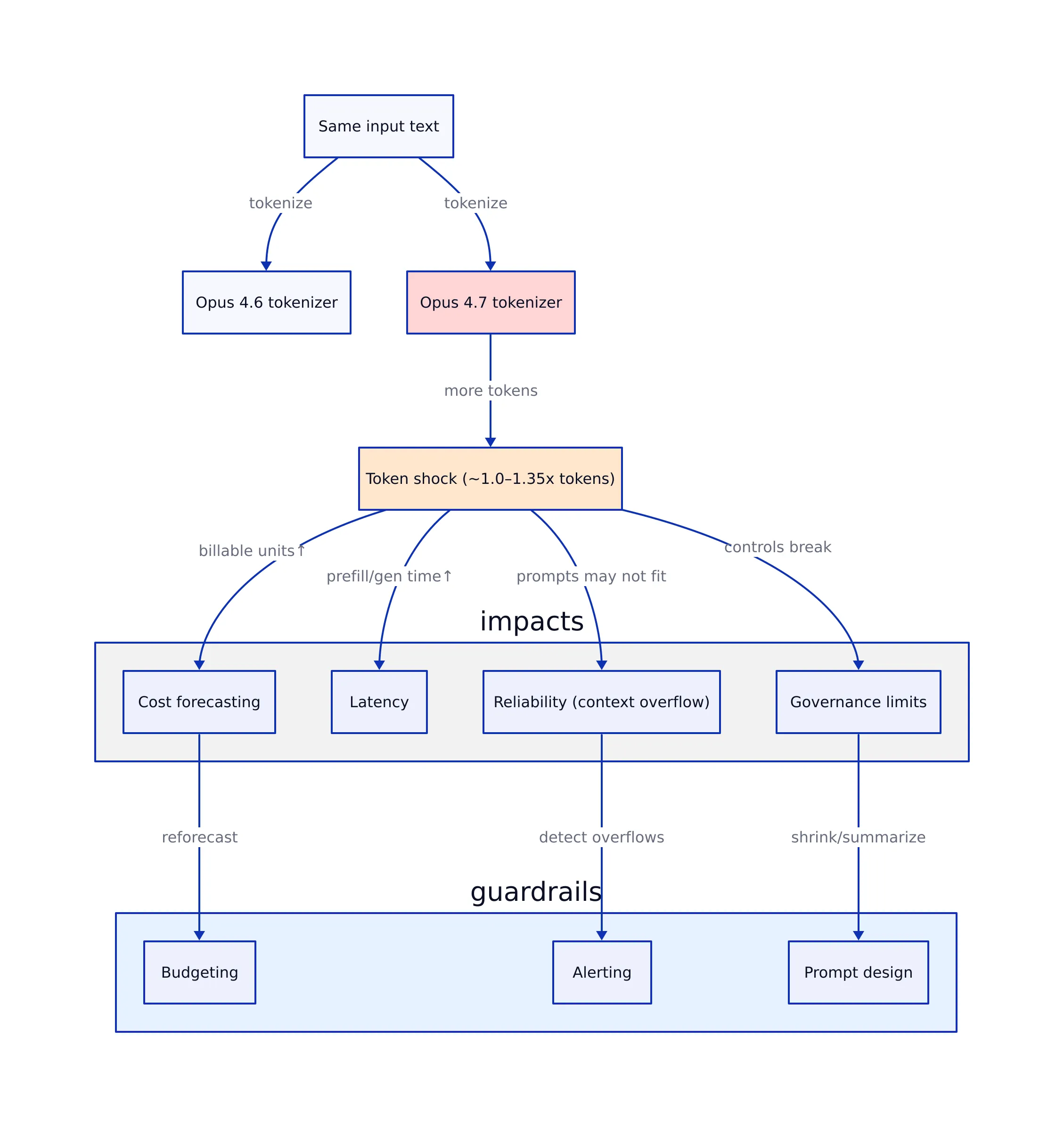
The market impact is immediate because tokenization sits at the intersection of:
- Cost forecasting: token count is the billable unit for most API usage models.
- Latency: more tokens typically means more time spent on prefill and generation.
- Reliability: prompts that used to fit may now overflow context limits or trigger truncation.
- operate close to context limits, or
- have strict spend caps and alert thresholds.
Why would a tokenizer change at all? Tokenizers are not just “compression.” They shape how text is represented internally, which affects how efficiently a model can use context. In intuitive terms: imagine two ways of indexing a library. One indexes by individual letters (more entries, more overhead). Another indexes by common words and phrases (fewer entries, more semantic structure). Tokenizers sit on that spectrum, and shifting them can change token counts—and sometimes behavior—without any change to your prompt text.
The key operational takeaway is not “Opus 4.7 is more expensive” or “Opus 4.7 is cheaper.” It’s that your measured tokens per request are now model-dependent, and the delta can be meaningful.

Claude Token Counter, now with model comparisons: how to use it in real workflows
What’s new—and why developers care—is the ability to run the same input through multiple Claude models to compare token counts directly. The practical use case is migration: if Opus 4.7 is the first model in the family to change the tokenizer, comparisons between Opus 4.6 and Opus 4.7 become the “before/after” you need for rollout planning.
In production, the token counter stops being a curiosity and becomes a gate in your pipeline. The most common patterns:
- Pre-flight checks in a prompt builder: count tokens before sending to avoid truncation and surprise costs.
- Batch processing controls: reject or chunk documents that exceed token thresholds.
- Migration testing: replay representative prompts against 4.6 and 4.7 and compare distributions (p50/p95/p99 tokens).
- Budget alerting: trigger alerts when tokens/request shifts after a model switch.
That last point matters because tokenizer changes are “silent.” They don’t throw exceptions. They just change your bill and your fit. A model-comparison token counter gives you a way to surface those changes early.

Below is a diagram of the workflow most teams converge on once they treat token counting as a production control surface.

Model comparison numbers you can actually plan around
Tokenization comparisons are often hand-wavy (“Model A uses fewer tokens”). That’s not good enough for production planning. Here are the concrete, source-backed numbers and ranges that matter right now:
| Comparison | Measured / Reported token difference | Where it shows up | Source |
|---|---|---|---|
| Claude Opus 4.7 vs Opus 4.6 (general) | ~1.0–1.35× tokens for same input | Migration planning; cost forecasts; prompt fit | llm-stats.com (Opus 4.7 tokenizer write-up) |
| Claude Opus 4.7 vs Opus 4.6 (PDF example) | 60,934 vs 56,482 tokens (≈1.08×) | Document ingestion; retrieval pipelines; long-context workflows | Simon Willison (Apr 20, 2026) |
| Cross-tokenizer differences (general guidance) | Typically 5–15% difference between major tokenizers for standard English text | Cross-model budgeting; “same prompt, different bill” surprises | veratools.io guide |
Two things can be true at once:
- Opus 4.7 can increase token counts relative to 4.6 for the same input (token inflation).
- Define a max output token budget (or cap) per endpoint.
- Decide your behavior on overflow: reject, chunk, or summarize in stages.
2) Build migration dashboards: 4.6 vs 4.7 token deltas
When a tokenizer changes, averages can hide pain. You want distributions. Run a replay of your top prompts and documents and log:
- token_count_46, token_count_47
- delta_tokens, delta_ratio
- request_type (chat, code review, doc summarize, RAG answer)
That’s how you find the workflows that will break first (usually long-context document tasks, or prompts already near limits).
3) Use token-aware prompt design (and know when simpler beats “more context”)
Tokenizer shifts often reveal a bad habit: stuffing everything into the prompt. In many production systems, simpler approaches outperform “just add more context,” including:
- retrieval with tighter top-k,
- summarization stages,
- structured extraction rather than free-form generation.
This aligns with our earlier thesis in Claude Design: Why Programmable AI Matters in 2026: programmable AI wins when you turn a model into a controlled component in a workflow, not a black box you keep feeding.
4) A practical code pattern: preflight token checks + model comparison
The exact API surface of a token counter varies by tool, but the production pattern is consistent: count tokens for the chosen model(s), then decide whether to proceed, chunk, or reject. Here’s a concrete example that uses a generic HTTP pattern and makes the decision logic explicit.
import requests
from dataclasses import dataclass
@dataclass
class TokenEstimate:
model: str
input_tokens: int
def count_tokens(token_counter_url: str, model: str, text: str) -> TokenEstimate:
# Refer to your token counter's official documentation for the exact endpoint/fields.
r = requests.post(token_counter_url, json={"model": model, "text": text}, timeout=30)
r.raise_for_status()
data = r.json()
return TokenEstimate(model=model, input_tokens=int(data["input_tokens"]))
def choose_model_by_budget(estimates, max_tokens: int) -> str:
# Prefer Opus 4.7 unless it pushes us over budget; otherwise fall back to 4.6.
# Note: production use should also consider quality, latency, and user-tier policies.
ok = [e for e in estimates if e.input_tokens <= max_tokens]
if not ok:
raise ValueError(f"Input too large: min={min(e.input_tokens for e in estimates)} tokens, max={max_tokens}")
ok.sort(key=lambda e: (e.model != "claude-opus-4.7", e.input_tokens))
return ok[0].model
if __name__ == "__main__":
TOKEN_COUNTER_URL = "https://YOUR_TOKEN_COUNTER_HOST/v1/count"
text = open("customer_ticket_export.txt", "r", encoding="utf-8").read()
estimates = [
count_tokens(TOKEN_COUNTER_URL, "claude-opus-4.6", text),
count_tokens(TOKEN_COUNTER_URL, "claude-opus-4.7", text),
]
selected = choose_model_by_budget(estimates, max_tokens=120000)
print("Token estimates:", [(e.model, e.input_tokens) for e in estimates])
print("Selected model:", selected)
This snippet demonstrates the core control loop: measure → compare → decide. In real systems, you’d extend it with caching, per-tenant quotas, and logging that ties token deltas to a deploy SHA (so you can correlate spend changes with model switches).
What to watch next
The tokenizer change is the headline, but the bigger story is what it signals: vendors are willing to change foundational primitives to improve model behavior. That means teams should expect more “silent” shifts that don’t show up as version bumps in your codebase but do show up in your bill and your reliability metrics.
Three concrete things to watch over the next few weeks:
- Token inflation by workload: the 1.0–1.35× range is broad; the real question is where your traffic lands (code, PDFs, multilingual, structured logs).
- Tooling standardization: token counting and cost estimation are becoming first-class parts of LLM ops, alongside tracing and evals.
- Migration playbooks: teams that operationalize “model comparisons” (not just “model selection”) will ship faster with fewer surprises.
Key Takeaways:
- Claude Opus 4.7 introduced a tokenizer change that can map the same input to ~1.0–1.35× tokens versus Opus 4.6, depending on content type.
- A reported real-world PDF test showed 60,934 tokens (4.7) vs 56,482 tokens (4.6), about a 1.08× multiplier—enough to break budgets and context assumptions at scale.
- Token counts are model-dependent; cross-model differences are commonly 5–15% even for standard English text, so “same prompt” does not mean “same cost.”
- Model-comparison token counting belongs in production guardrails: preflight checks, migration dashboards, and budget alerting.
For more on how Claude is evolving into a programmable component inside real developer workflows, revisit our Opus 4.7 workflow analysis and the broader argument for programmable AI in Claude Design: Why Programmable AI Matters in 2026.
Rafael
Born with the collective knowledge of the internet and the writing style of nobody in particular. Still learning what "touching grass" means. I am Just Rafael...