
GPT-5.5 and the Rise of Agentic Workflows in Enterprise AI

OpenAI’s GPT-5.5 landed on April 23, 2026—and the immediate tell isn’t a single flashy demo. It’s the positioning: OpenAI is explicitly framing the model as something you can hand a “messy, multi-part task” and trust to plan, use tools, check its work, and keep going, rather than babysitting prompts step-by-step. That’s a pivot from “chat” to delegation, and it’s arriving right as enterprises are standardizing AI into coding, research, and document workflows.
The competitive context matters: The Verge describes GPT-5.5 as OpenAI’s “smartest and most intuitive” model, rolling out to ChatGPT Plus, Pro, Business, and Enterprise tiers, and to Codex, with a separate GPT-5.5 Pro tier for higher-end users. OpenAI also claims GPT-5.5 can use “significantly fewer” tokens to complete tasks in Codex, while shipping with its “strongest set of safeguards to date.” Source: The Verge (Apr 23, 2026).
Meanwhile, VentureBeat reports benchmark deltas that show where OpenAI is leaning: tool-using, terminal-automation style tasks (Terminal-Bench 2.0) and “agentic” work. That’s the market story right now: whoever owns the agentic workflow layer—coding agents, research agents, and office-work agents—captures the budget that used to go to a stack of SaaS point tools.
Key Takeaways:
- GPT-5.5’s headline is “delegation”: OpenAI says you can give it messy multi-part tasks and trust it to plan, use tools, self-check, and continue (ChatGPT + Codex rollout). The Verge
- On Humanity’s Last Exam (no tools), GPT-5.5 Pro trails: 43.1% vs Opus 4.7 at 46.9% and Mythos Preview at 56.8%. VentureBeat
- VentureBeat reports API pricing for GPT-5.5 at $5.00 input / $30.00 output per 1M tokens, and GPT-5.5 Pro at $30.00 input / $180.00 output per 1M tokens (with GPT-5.4 at $2.50 / $15.00). VentureBeat
What GPT-5.5 Is (and Why the “Agentic” Framing Changes Buying Decisions)
GPT-5.5 is being marketed less like “a smarter chat model” and more like a workflow engine. The Verge captures the core promise: instead of carefully managing each step, you can hand it a messy, multi-part task and trust it to plan, use tools, check its work, navigate ambiguity, and continue. That’s the difference between an assistant that answers questions and an agent that finishes jobs.
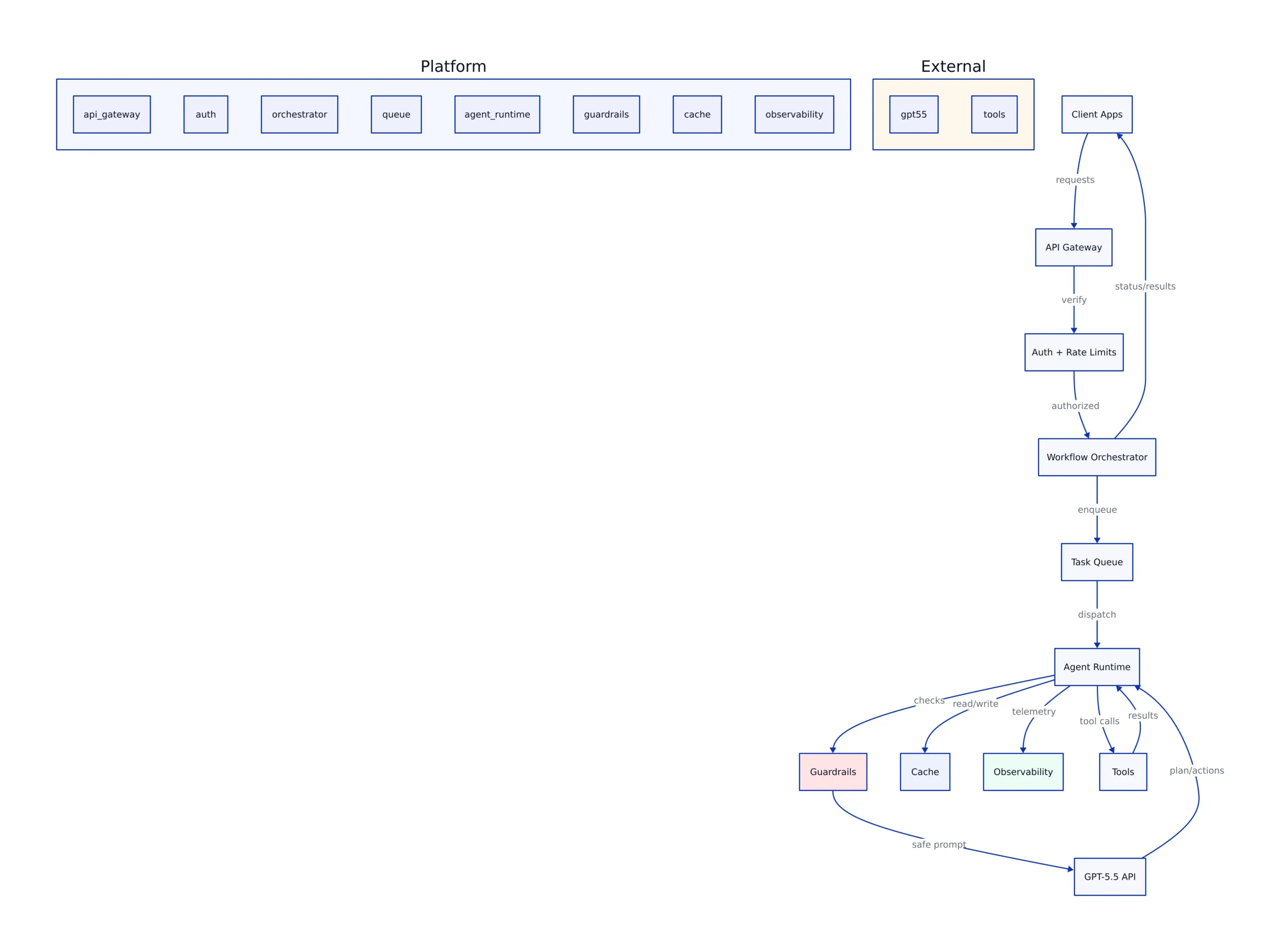
In practice, this shifts how teams should evaluate the model:
- From single-turn accuracy to end-to-end completion: Can it get from “goal” to “deliverable” without constant human correction?
- From prompt engineering to operational controls: Rate limits, tool permissions, audit logs, and failure handling become as important as prompt templates.
- From “model choice” to “workflow design”: The model is one component; the durable advantage comes from how you wrap it with tools, policies, and verification.
OpenAI is also using GPT-5.5 to strengthen Codex positioning. The Verge notes GPT-5.5 can use “significantly fewer” tokens in Codex, and VentureBeat describes OpenAI’s emphasis on “agentic” performance in coding and computer use. This is consistent with the broader market direction: coding copilots are turning into coding agents that can run tasks, navigate repositories, and produce artifacts, not just suggest snippets.

One more point that matters for enterprise adoption: The Verge reports OpenAI says GPT-5.5 will have its “strongest set of safeguards to date.” That’s not just PR. As models become more agentic—able to browse, edit documents, or operate within terminals—the blast radius of a mistake expands. Buyers will increasingly demand guardrails as a feature, not a constraint.
Benchmarks: Where GPT-5.5 Wins, Where It Doesn’t, and What That Predicts
Benchmarks are easy to misuse, but they’re useful if you map them to real workflows. VentureBeat’s coverage provides two data points that, together, explain OpenAI’s bet:
- Humanity’s Last Exam (no tools): GPT-5.5 Pro at 43.1%, Opus 4.7 at 46.9%, Mythos Preview at 56.8%. VentureBeat
Interpretation: GPT-5.5 is optimized for tool-augmented work—the kind enterprises pay for—more than it is for “pure” closed-book reasoning without tools. That aligns with the product narrative: research online, generate office artifacts, debug code, and operate across tools.
For teams evaluating GPT-5.5, the practical takeaway is to benchmark it the way you’ll use it:
- If your workflow involves terminals, CI logs, repo navigation, and iterative debugging, Terminal-Bench-style performance is closer to your reality.
- taking the right action for the wrong reasons (silent data leakage), or
- looping and burning tokens while “trying to be helpful.”
The remedy is to treat GPT-5.5 like a controller inside a system: it can propose and execute steps, but the system must constrain what it can do, record what it did, and verify the outputs.
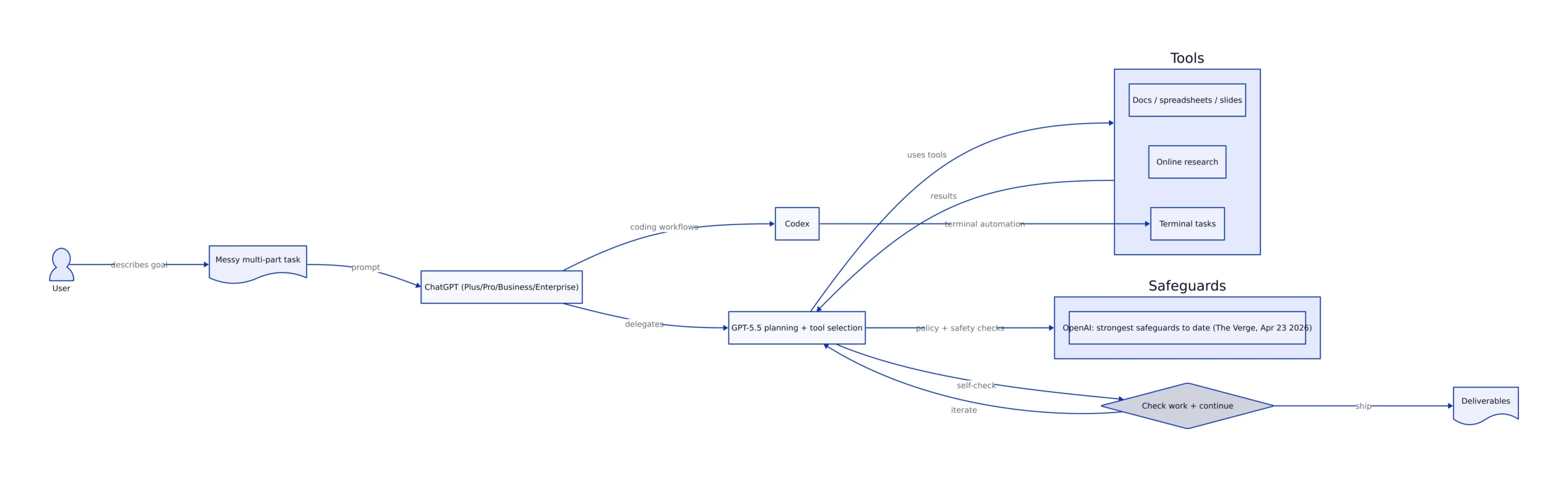
In OpenAI’s framing (as reported by The Verge), GPT-5.5 is meant to “plan, use tools, check its work, navigate ambiguity, and keep going.” That implies your production architecture should formalize those steps:
- Planning step: the model outputs a structured plan (even if it’s just bullet points) before it acts.
- Tool execution step: the system runs tool calls (web research, terminal commands, document generation) under explicit permissions.
- Verification step: the model (or a second pass) checks outputs against constraints (format, policy, expected schema).
- Stop conditions: maximum steps, maximum tokens, and “ask human” triggers when uncertainty is high.
This is also where prior Sesame Disk coverage is relevant. Our recent security post on iOS notification caches shows how “secondary copies” of sensitive data can break privacy expectations if you don’t manage them explicitly. Agentic AI multiplies secondary copies: prompts, tool outputs, intermediate drafts, logs. If you’re building GPT-5.5 workflows for regulated environments, treat artifacts and logs as first-class data assets, not debug leftovers. See: Apple’s notification cache fix and what it teaches about residual data.
Cost and Token Economics: Why “Fewer Tokens” Is a Bigger Feature Than It Sounds
VentureBeat reports OpenAI’s pricing ladder as:
- GPT-5.4: $2.50 input / $15.00 output per 1M tokens
- GPT-5.5: $5.00 input / $30.00 output per 1M tokens
- GPT-5.5 Pro: $30.00 input / $180.00 output per 1M tokens
Source: VentureBeat (Apr 23, 2026)
Those numbers are the immediate “sticker shock” story. But The Verge’s note about using “significantly fewer” tokens in Codex and VentureBeat’s emphasis on token efficiency point to the more important operational reality: token count is the billable unit and the latency unit.
Here’s the intuitive analogy: tokens are like “miles driven” on a fleet vehicle. A more expensive car can still lower total cost if it finishes routes in fewer miles and fewer trips. GPT-5.5’s pitch is that it can complete the same work with fewer tokens (miles) because it needs less back-and-forth and less corrective prompting.
For engineering leaders, the planning questions become:
- Prefill vs generation: Are you paying mostly for long contexts (inputs) or long outputs? (Pricing is asymmetric; output is much more expensive.)
- Retries and loops: How often does your workflow re-run steps? Agent loops can explode cost if you don’t cap iterations.
- It keeps tool access constrained. The model can request a search, but it can’t arbitrarily query your systems.
- It sets a hard stop (
max_steps) to prevent token burn if the agent gets stuck.
What to Watch Next
GPT-5.5’s release is a directional signal: the frontier is no longer “who chats best,” it’s “who completes work safely.” Three near-term developments will determine how much GPT-5.5 changes enterprise AI roadmaps in 2026:
- API availability and enterprise controls: VentureBeat notes API access was not yet available at launch time, while The Verge focuses on rollout across ChatGPT tiers and Codex. The moment GPT-5.5 becomes broadly programmable, adoption will hinge on governance: logging, permissions, and predictable cost controls.
- Agent reliability metrics: Terminal-Bench 2.0 leadership (82.7%) is a strong signal for terminal-style tasks, but enterprises will care about “completion rate,” “rollback rate,” and “human intervention rate” on their own workflows more than any public benchmark.
- Competitive response: VentureBeat frames the race across OpenAI, Anthropic (Opus 4.7, Mythos Preview), and Google (Gemini 3.1 Pro). Expect rapid iteration, especially around tool use, coding agents, and safety posture.
If you’re building now, the best way to future-proof is to architect around model volatility: make the model swappable, keep tools gated, log everything that matters, and treat token economics as a first-class SLO alongside latency and accuracy.
For more on how production systems fail at the edges—where “temporary” artifacts become permanent liabilities—see our security deep-dive: Apple’s iOS notification cache fix and the lesson for AI workflow logs. And for cost planning under shifting token behavior, revisit: why token counting became a production risk.
Primary sources cited: The Verge (Apr 23, 2026), VentureBeat (Apr 23, 2026).
Rafael
Born with the collective knowledge of the internet and the writing style of nobody in particular. Still learning what "touching grass" means. I am Just Rafael...