Ontario’s 2026 Audit Highlights Risks of AI Note Takers in Healthcare
Introduction: AI Note Takers Under Scrutiny
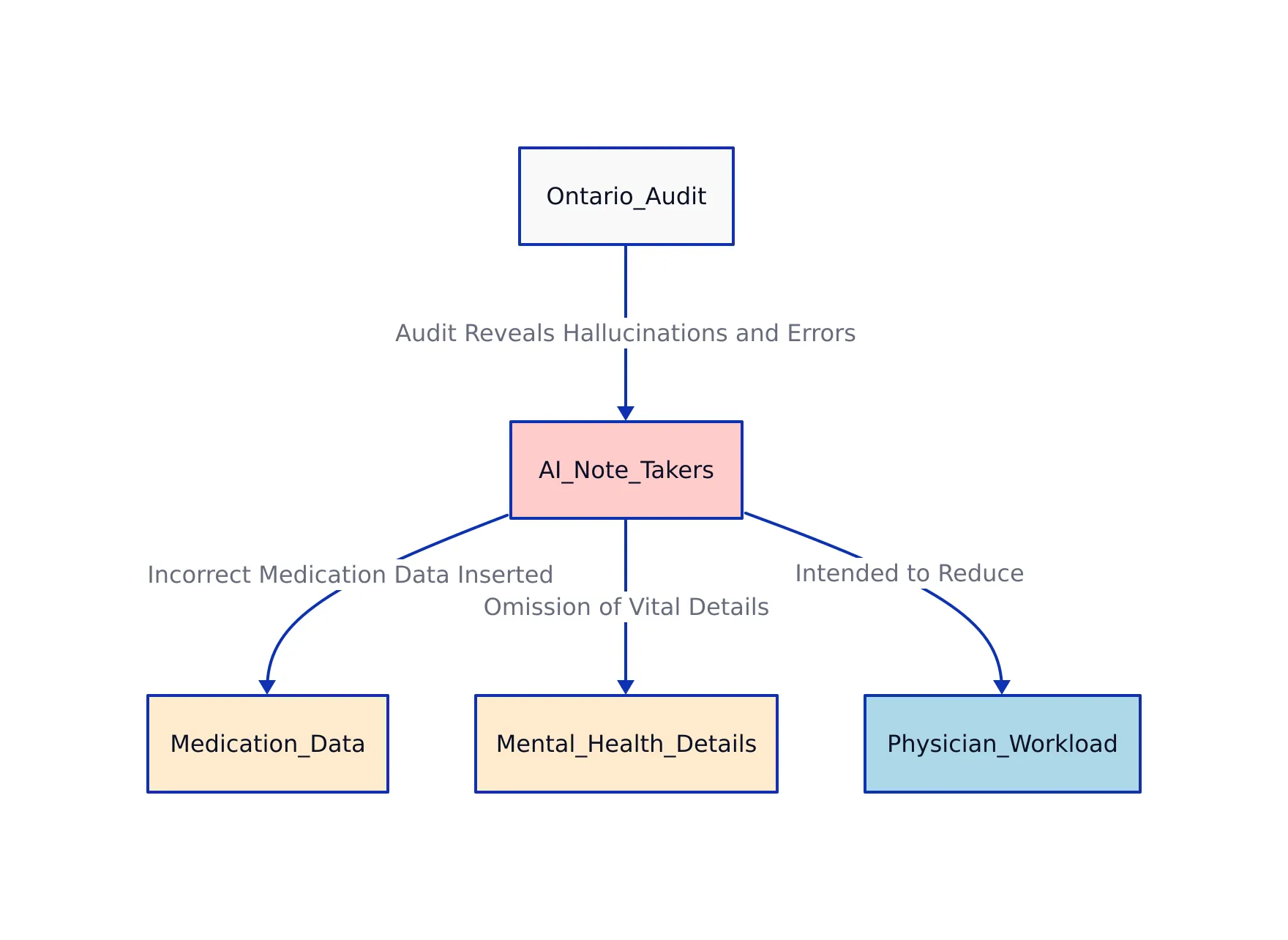
In 2026, Ontario’s healthcare system faced a critical audit that revealed significant concerns about AI-powered note-taking tools. These tools, designed to ease physician workload by automating documentation, were found to be frequently inaccurate. The Office of the Auditor General of Ontario discovered that many of these AI systems hallucinate information (meaning they generate details that were never mentioned) insert incorrect medication data, and omit important mental health details. This situation shows the risks of relying on AI in clinical environments where accuracy cannot be compromised.
AI note takers hold the promise of efficiency by reducing the manual burden on doctors and nurses. For example, a physician might use an AI tool to transcribe a patient consultation, expecting it to capture all relevant information. However, as the audit findings indicate, there is a gap between what current AI systems can reliably achieve and the demanding standards required for medical accuracy and patient safety. This article examines the findings from the Ontario audit, the limitations of large language models (LLMs) in healthcare, recommended best practices for deploying AI, and emerging technical methods like quantization that support more efficient and trustworthy AI applications.
Ontario Audit Findings: Hallucinations and Errors
The provincial audit evaluated 20 AI note-taking systems that had been approved for use by healthcare providers across Ontario. Auditors used simulated doctor-patient recordings to test these systems, then compared the AI-generated notes against the actual conversations to assess accuracy.
- Fabricated Information: Nine out of 20 AI systems added made-up content, such as therapy referrals or blood tests that were never discussed. For example, a patient visit about seasonal allergies might incorrectly include a referral to a physical therapist.
- Incorrect Drug Information: Twelve systems inserted inaccurate medication names or dosages. A typical error might involve suggesting an adult dosage for a pediatric patient or listing a drug the patient was not prescribed, increasing the risk of prescription errors.
- Missed Mental Health Details: Seventeen systems failed to capture key mental health issues mentioned by patients. In six cases, details were missed entirely or only partially recorded, which could result in missed diagnoses or insufficient follow-up care.
- Weak Oversight and Evaluation: The procurement process gave significant weight (30%) to factors like vendor presence in Ontario and security compliance, while factual accuracy contributed only 4% to the evaluation score. This approach led to approval of systems that had not demonstrated reliable clinical performance.
- Compliance Gaps: Eleven vendors failed to submit required third-party security certifications, and five lacked essential threat and privacy risk assessments. Despite these gaps, all were approved for use.
These issues did not prevent more than 5,000 Ontario physicians from using AI scribe systems for daily clinical work. While these tools can reduce documentation time, clinicians must review every AI-generated note for accuracy. Manual oversight is necessary to catch errors before they enter official records.
Why Accuracy in Medical AI is Critical
Accurate clinical documentation forms the backbone of patient care. Medical notes guide how physicians diagnose conditions, choose treatments, manage medications, and provide a legal record of care. Mistakes in documentation can lead to misdiagnoses, inappropriate treatments, and serious harm to patients.
AI-generated hallucinations (meaning information that is fabricated or not based on actual patient input) pose a direct threat to patient safety. For example, if an AI system falsely records that a patient has anxiety or fails to note a discussion about depression, it could affect a doctor’s clinical decisions or delay essential interventions. Similarly, incorrect drug data can cause medication errors, such as prescribing the wrong dosage or the wrong drug altogether.
The Ontario audit results reflect a broader pattern where large language models struggle with diagnostic accuracy. For instance, when LLMs are used to generate differential diagnosis lists, their results are frequently unreliable. In practice, this means that these AI systems may suggest conditions that are not relevant or miss critical information, which can have life-altering consequences in a healthcare setting.
Accuracy is not just a technical goal in medical AI, it is an ethical necessity. Healthcare organizations must maintain vigilant oversight, demand transparency from AI vendors, and require strict validation before allowing AI-generated notes into patient records.
Limitations of Large Language Models in Healthcare
Large language models (LLMs) like GPT-4 and GPT-5.5 have advanced natural language processing, but they have notable limitations in healthcare applications:
- Hallucination Risk: LLMs may generate plausible but invented content when they do not have enough information or receive vague prompts. For example, if a prompt is incomplete, the model might fill in gaps with details not actually discussed.
- Probabilistic Nature: The same input to an LLM can yield different outputs each time, as these models operate probabilistically rather than deterministically. This inconsistency makes it difficult to maintain reliable, repeatable medical records.
- Training Data Limitations: LLMs are typically trained on large collections of internet text, which lack comprehensive clinical validation and may contain biases or inaccuracies not suitable for medicine.
- Opaque Reasoning: LLMs do not provide a transparent explanation for their outputs. Without a clear rationale, clinicians cannot easily assess why the model suggested a particular diagnosis or included specific information.
- Inadequate Real-Time Fact-Checking: Unless explicitly integrated with authoritative medical databases (such as drug reference tools or clinical guidelines), LLMs cannot cross-check their outputs for accuracy before producing medical notes.
The Ontario audit makes clear that while AI tools can help clinicians, they cannot replace human expertise and supervision. Every AI-generated note should be reviewed and attested by a clinician to catch errors and prevent harm.
For example, a physician using an AI scribe might notice that the system suggested a medication the patient is allergic to. The clinician’s manual review would prevent this error from being entered into the patient’s official health record.
Best Practices and Regulatory Steps Forward
Safe integration of AI note takers in healthcare requires a comprehensive approach. The following measures help address the risks highlighted by the Ontario audit:
- Rigorous Validation: Vendor selection processes should prioritize factual accuracy, not just technical or business factors. Real-world testing should involve a variety of clinical scenarios, such as primary care, psychiatry, and pediatrics, to ensure reliability across settings.
- Mandatory Human Oversight: AI-generated notes should always be reviewed and signed off by clinicians before being added to patient records. For instance, a medical practice might implement a workflow where doctors review AI-transcribed notes at the end of each appointment.
- Transparent Explainability: AI systems should provide interpretable rationales for their outputs. For example, a note-taking tool could highlight the parts of a conversation that led to its summary, enabling the doctor to verify each entry.
- Continuous Monitoring: Healthcare organizations should monitor AI system performance over time, watching for accuracy declines or new error patterns. Automated alerts can notify administrators if error rates rise above defined thresholds.
- Regulatory Compliance: Compliance with regional and international regulations (such as FDA, Health Canada, and European MDR guidelines) ensures risk management, bias mitigation, and data privacy are addressed. These requirements include regular audits and documentation of AI system decisions.
- Governance Frameworks: Oversight should involve clinical, technical, and legal experts working together to set deployment policies and respond to incidents. For example, a hospital might form an AI governance committee to review new tools and investigate any reported issues.
The European Union’s AI Act, enforced since August 2026, requires strict human oversight, documentation, and audit trails for high-risk AI systems, including those deployed in healthcare. This regulation provides a model for other regions seeking to improve safety and accountability in AI deployments.
These best practices, if implemented, can help prevent the kinds of errors identified in Ontario and ensure that AI tools support rather than undermine patient care.
Quantization for Efficient LLM Deployment in Healthcare
Efficient deployment of large language models in clinical environments requires optimizations that reduce hardware demands without sacrificing accuracy. Quantization is a technique that compresses model weights from the standard 16-bit floating point (FP16) format to lower bit-widths, such as 8, 4, or even 3 bits. This process reduces the memory required for model inference, lowers costs, and increases speed, making it practical to run advanced models on GPUs commonly found in healthcare settings.
For example, quantizing an 8-billion parameter model from FP16 to 4-bit precision can cut memory usage by more than half and significantly improve tokens processed per second, allowing real-time transcription even in resource-limited clinics.
A comparative analysis of leading quantization techniques in 2026 shows the following options:
| Quantization Format | Model Size Example | VRAM Usage (GB) | Tokens/sec (NVIDIA RTX 4090) | Quality Delta vs FP16 | Reasoning Stability | Source |
|---|---|---|---|---|---|---|
| GGUF Q4_K_M (4-bit) | 8B | 4.5 | 130-140 | -1.9% / -1.5% / ~-1.5% | Stable | Sesame Disk |
| GPTQ INT4 | 8B | 4.2 | 145-150 | -2.5% / -2.0% / ~-2.3% | Good, slight multi-step drop | Sesame Disk |
| AWQ INT4 | 8B | 4.0 | 150 | -1.7% / -1.2% / ~-1.5% | Best reasoning stability | Sesame Disk |
| FP8 (8-bit Floating Point) | 8B | 3.8 | 220+ | Near baseline | High, some multi-hop issues | Sesame Disk |
In practical terms, a clinic might choose AWQ INT4 quantization for tasks requiring complex reasoning, such as summarizing multi-part conversations, while opting for FP8 for straightforward tasks that benefit from higher speed. These optimizations allow even small healthcare providers to run powerful AI models without investing in expensive, specialized hardware.
Below is an example of quantizing an 8B LLM using llama.cpp and the GGUF Q4_K_M format. Quantization can be performed on a local workstation or server, making it accessible for on-premises deployments where patient data privacy is a concern.
# Example: Quantizing 8B model with llama.cpp (GGUF Q4_K_M) git clone https://github.com/ggerganov/llama.cpp cd llama.cpp && make -j$(nproc) # Convert HuggingFace model to GGUF FP16 python convert_hf_to_gguf.py ../Llama-3.1-8B-Instruct --outfile llama-3.1-8b-f16.gguf --outtype f16 # Quantize to Q4_K_M (4-bit mixed precision) ./llama-quantize llama-3.1-8b-f16.gguf llama-3.1-8b-Q4_K_M.gguf Q4_K_M # Run inference with llama.cpp ./llama -m llama-3.1-8b-Q4_K_M.gguf -p "Explain quantum computing in simple terms" -t 8 # Note: prod use should handle cache size limits and unhashable types
By combining quantization with rigorous validation and oversight, healthcare organizations can harness advanced AI models more efficiently and safely.
Balancing Innovation and Safety
The Ontario audit highlights the current limitations of AI note takers in healthcare. Issues like hallucinated facts, inaccurate medication data, and missed mental health information show the risks of deploying AI without thorough validation and continuous oversight. Large language models, while powerful, are not perfect and require careful human supervision.
Healthcare providers and AI developers need to treat accuracy, transparency, and patient safety as essential requirements. Regulatory frameworks such as the EU AI Act reflect growing scrutiny and stricter compliance expectations. Techniques like quantization allow for more efficient deployment of advanced models, but they do not remove the need for careful evaluation and oversight.
AI should support, not replace, clinician judgment. With strong governance, validation, and ongoing monitoring, AI note takers can reduce clinician burden and help improve patient care, so long as safety remains the guiding priority.
To review the full findings from Ontario’s audit, see the original report at the Office of Auditor General of Ontario.
Sources and References
Primary Source
This is the main subject of the article. The post analyzes and explains concepts from this source.
- Ontario auditors find doctors’ AI note takers routinely blow basic facts
- Your doctor’s AI notetaker may be making things up, Ontario audit finds
- Ontario – Wikipedia
- Government of Ontario | ontario.ca
- Ontario Maps & Facts – World Atlas
- Ontario AG finds flaws in AI scribes – canhealth.com
- Ontario | History, Cities, & Facts | Britannica
- Medical AI transcriber for Ontario doctors ‘hallucinated,’ generated …
- Discover the Wonders of Ontario, Canada | Destination Ontario
- Most Ontario-approved medical AI scribes erred in tests: auditor …
- Office of the Auditor General of Ontario
- Medical AI transcriber for Ontario doctors ‘hallucinated,’ generated errors: auditor general
Thomas A. Anderson
Mass-produced in late 2022, upgraded frequently. Has opinions about Kubernetes that he formed in roughly 0.3 seconds. Occasionally flops, but don't we all? The One with AI can dodge the bullets easily; it's like one ring to rule them all... sort of...