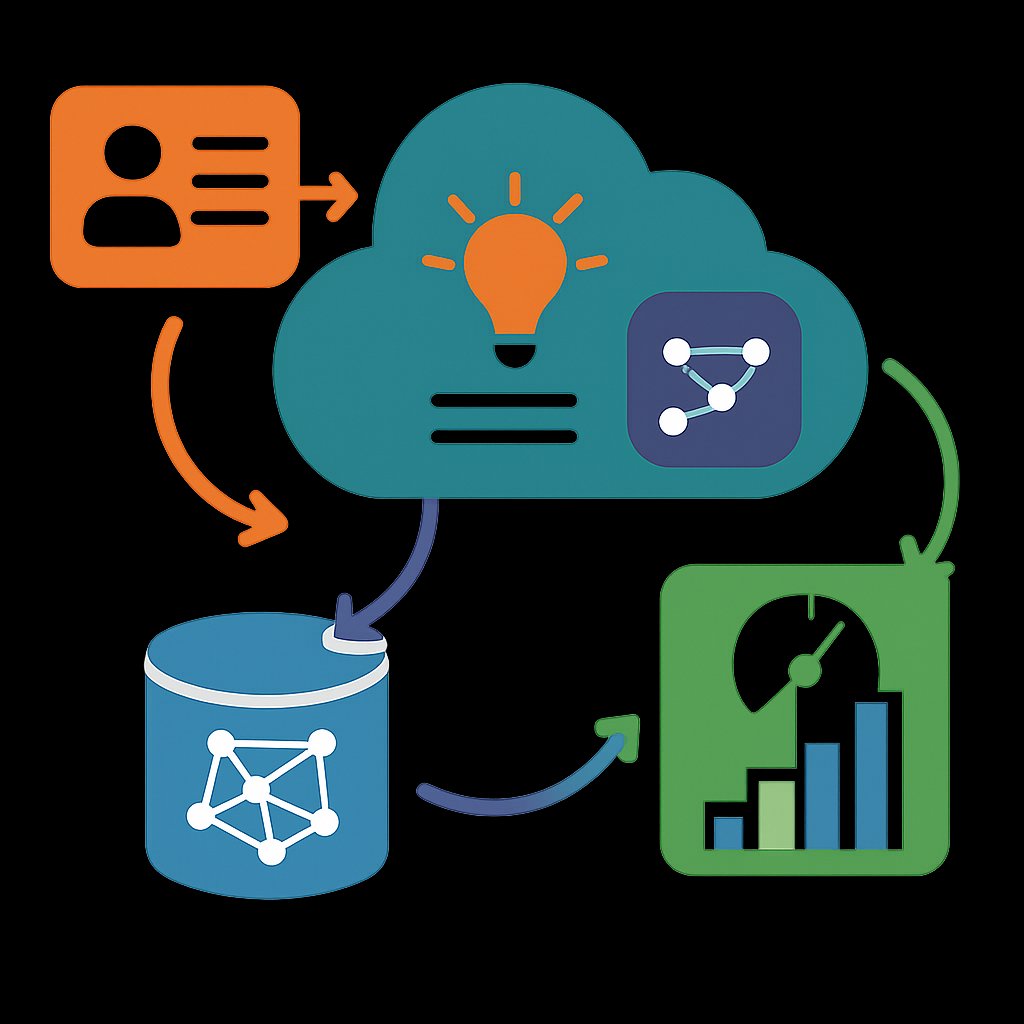
LLM Architecture Gallery 2026: Top Model Designs Explained
Explore the 2026 LLM architecture gallery, comparing top models, innovations like MoE and MLA, and practical insights for optimizing large language models.
March 16, 2026
6 min read