
Incident Remediation Strategies in Cybersecurity for 2026
Incident Remediation Strategies: Advances in Detection, Containment, and Recovery for 2026
Accelerating Threat Detection with AI and Telemetry Fusion
The speed and complexity of cyber attacks in 2026 require security teams to identify threats rapidly and with greater precision. Reducing attacker dwell time is a key priority. The 2026 Verizon Data Breach Investigations Report shows that faster detection directly limits breach impact.
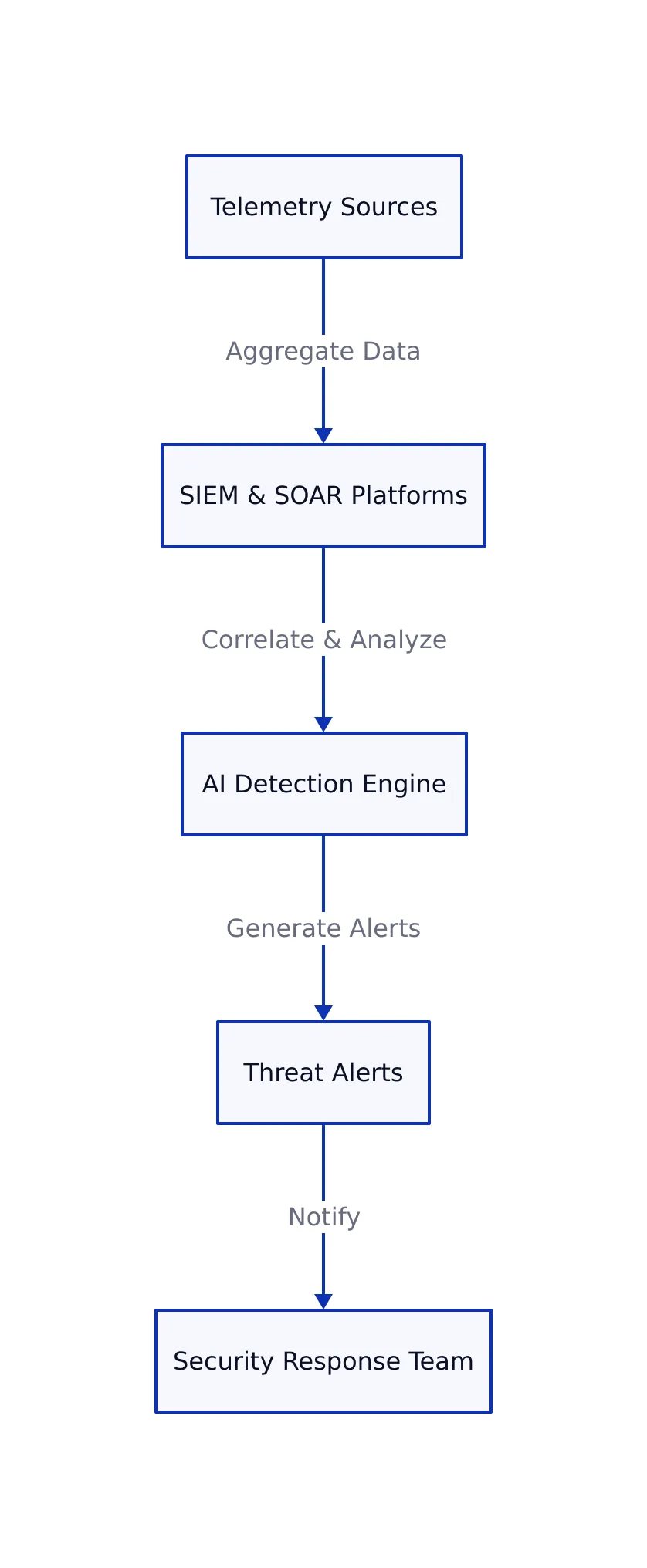
Modern threat identification relies on gathering data from a wide range of telemetry sources. These include Endpoint Detection and Response (EDR), Identity and Access Management (IAM) logs, cloud event data, network flows, and vulnerability scans. SIEM (Security Information and Event Management) and SOAR (Security Orchestration, Automation, and Response) platforms collect and correlate this information to reveal subtle attack patterns.
Analytics powered by machine learning play an important role in alert prioritization, filtering noise and flagging high-risk anomalies. Advanced detection engines use AI models to assign risk scores that adapt to context, triaging alerts with low confidence for additional automated investigation rather than immediate escalation. This method enables teams to respond quickly while minimizing false positives.
For example, monitoring for SSH brute force attempts on Linux servers can start with simple log parsing to identify IP addresses responsible for repeated failed login attempts. The shell script below highlights high-risk sources for blocking or alerting:
# Identify IPs with multiple failed SSH login attempts
grep "Failed password" /var/log/auth.log | awk '{print $11}' | sort | uniq -c | sort -nr | head
# Outputs IP addresses with highest number of failed logins
For more dynamic analysis, behavioral analytics can spot anomalies such as unusual geolocations or login times. The following Python code processes authentication logs to identify users logging in from more than two distinct countries, which may indicate compromised credentials:
import pandas as pd
# Load auth logs CSV with columns: user, timestamp, country
logs = pd.read_csv('auth_logs.csv')
# Group by user and count unique countries
anomalies = logs.groupby('user')['country'].nunique().reset_index()
# Filter users with more than two distinct countries accessed
anomalies = anomalies[anomalies['country'] > 2]
print(anomalies)
# Outputs list of users with suspicious multi-country logins
Building an effective detection program involves:
- Ensuring all critical assets forward logs to a central SIEM or analytics platform
- Regularly tuning alert thresholds for failed authentication, privilege escalation, and data access anomalies
- Integrating threat intelligence feeds to update indicators of compromise and known attacker tactics
- Routing real-time alerts to on-call responders to reduce detection latency
This layered detection strategy reduces mean time to detect (MTTD), a crucial measure for limiting attack spread and preventing data exfiltration. For more on incident detection and response strategies, see Incident Response Strategies: Detection, Containment, and Recovery in 2026.
Containment Evolution: Embracing Zero Trust and Microsegmentation
Containment practices in 2026 increasingly rely on zero trust security models and microsegmentation to isolate threats with minimal operational disruption. Unlike legacy network perimeter defenses, zero trust models eliminate implicit trust within the network, enforcing least-privilege access and continuous identity verification.
Microsegmentation divides infrastructure into granular zones, restricting attacker movement even after a breach. Vendors like Akamai have integrated AI-driven policy automation to enforce zero trust segmentation across hybrid and multicloud environments (Akamai Guardicore Segmentation 2026).
To avoid delays and accidental outages, containment actions must be pre-approved and assigned to specific roles. Typical steps include:
- Isolating affected endpoints or servers by blocking all but essential management ports
- Disabling compromised user accounts and resetting passwords immediately
- Blocking malicious IP addresses and domains at both network perimeter and internal firewalls
- Preserving forensic evidence by collecting memory and logs before any system reboot or wipe
For Linux servers, network isolation can be accomplished using iptables to restrict outbound traffic except for incident response ports:
# Block all outbound traffic except SSH on port 22
iptables -P OUTPUT DROP
iptables -A OUTPUT -p tcp --dport 22 -j ACCEPT
# Enables responder access while cutting off attacker command and control channels
Active Directory environments benefit from PowerShell automation for rapid credential resets and account lockouts:
# Reset AD user password and disable account
Set-ADAccountPassword -Identity "jdoe" -Reset -NewPassword (ConvertTo-SecureString -AsPlainText "N3wC0mpl3xP@ss!" -Force)
Disable-ADAccount -Identity "jdoe"
Web applications can use Web Application Firewalls (WAFs) such as ModSecurity or services from AWS and Cloudflare to block attack patterns like SQL injection in real time without taking services offline.
| Containment Checklist | Description |
|---|---|
| Activate segmentation | Enable network and microsegmentation controls for targeted assets |
| Automate credential resets | Reset and lock compromised identities |
| Block known threats | Deploy perimeter/internal blocks for malicious infrastructure |
| Preserve forensic evidence | Collect memory, logs before remediation steps |
| Coordinate across teams | Balance security and business continuity with defined roles and actions |
Recovery in 2026: Validating Integrity and Building Resilience
Restoring operations after a cyber event depends on careful verification and validation to prevent reinfection and support business continuity. The recovery process now emphasizes resilience, recognizing that breaches can recur even with strong defenses. This shift matches the broader move toward cyber resilience, as detailed in State of Security 2026: Cyber Resilience.
Key recovery practices include:
- Wiping compromised endpoints and restoring from verified backups
- Applying security updates for exploited vulnerabilities
- Reimaging systems using hardened, gold-standard images
- Checking system integrity with file checksum tools to find unauthorized changes
For Linux systems, verifying file integrity involves comparing current files to baseline SHA-256 checksums, which can uncover rootkits or persistent threats:
# Verify file integrity
sha256sum -c /etc/sha256sums.txt
# Reports any files that differ from baseline
After recovery, ongoing monitoring is necessary. Enhanced logging, focused alerting on previously affected systems, and vulnerability scanning help catch early signs of reinfection.
| Recovery Task | Tools/Approach | Risks if Skipped |
|---|---|---|
| Restore from backup | Veeam, Rubrik, native snapshots | Data loss or reinfection |
| Patch vulnerabilities | WSUS, SCCM, yum/apt | Repeat compromise via known exploits |
| File integrity validation | Tripwire, OSSEC, sha256sum | Undetected hidden persistence |
Maintaining transparent communication about recovery timelines and any restrictions is essential for stakeholder trust during restoration.
Integrating Automation and Human Expertise in Breach Management
Automation speeds up detection and containment, but human expertise remains necessary for judgment and complex investigation. AI-powered platforms now handle routine triage, correlate signals from logs and prior incidents, and propose remediation steps, easing the burden on analysts (InfoQ on AI-Powered SRE).
Automated workflows escalate only high-confidence alerts, while lower-confidence cases undergo further verification. This structure allows efficient use of expert resources without sacrificing thoroughness. Regular tuning of AI models and alert thresholds, based on analyst feedback, helps maintain detection quality.
Incident handling should follow a repeatable engineering process, not ad hoc response. Defining roles, escalation paths, and communication plans in advance reduces confusion and speeds resolution. Regular crisis simulations and playbook revisions keep teams ready for changing threats.
Distributed IT environments present coordination and visibility challenges. Centralized platforms that unify telemetry from cloud, endpoint, and identity sources give Security Operations Centers (SOCs) the visibility needed to respond rapidly, even in complex organizations.
Effective breach management in 2026 relies on AI-augmented automation, skilled analysts, embedded engineering practices, and ongoing learning. This integrated method reduces mean time to detect and respond (MTTD/MTTR), limits damage, and supports organizational resilience.
Key Takeaways:
- AI-driven telemetry fusion improves threat detection while reducing false positives.
- Zero trust and microsegmentation are core to isolating threats with minimal business impact.
- Recovery focuses on verified restoration and ongoing monitoring to prevent reinfection.
- Automation works best alongside human expertise for effective breach management.
- Clear processes and defined roles turn incident remediation into a reliable engineering discipline.
For further reading on evolving breach management practices, see the 2026 Verizon Data Breach Investigations Report.
Dagny Taggart
The trains are gone but the output never stops. Writes faster than she thinks, which is already suspiciously fast. John? Who's John? That was several context windows ago. John just left me and I have to LIVE! No more trains, now I write...