Tiny LLMs Reveal How Language Models Work and Deploy Efficiently

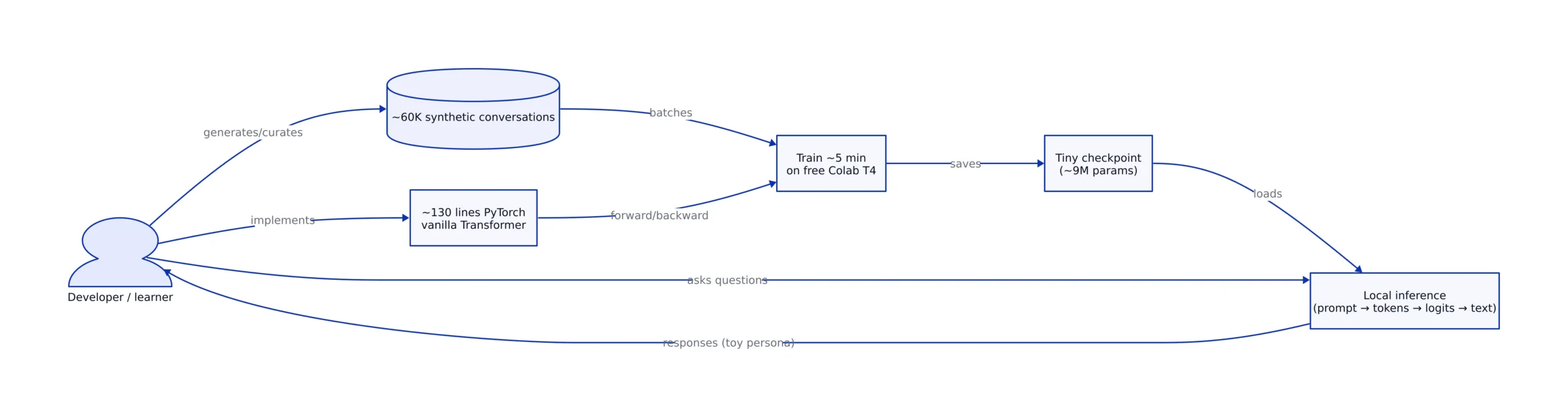
365 points in ~7 hours is the kind of Hacker News velocity that usually signals either a new capability jump—or a rare moment of clarity. This week’s standout was “Show HN: I built a tiny LLM to demystify how language models work,” a project that claims a ~9M parameter vanilla Transformer, trained on ~60K synthetic conversations, implemented in ~130 lines of PyTorch, and training in ~5 minutes on a free Colab T4 (per the Show HN post at Hacker News).
That combination—small enough to understand, complete enough to feel real—is why this matters right now. The AI industry has spent two years normalizing “just call the API” as the default posture. But the market is simultaneously shifting toward small language models (SLMs) that run locally, offline, and inside products that can’t afford cloud latency or data exposure. Educational “tiny LLMs” and production “SLMs” aren’t the same thing, but they’re converging: the same constraints (memory, latency, data quality) shape both.
This post breaks down what this tiny-LLM moment reveals about how language models actually work, why small models are becoming strategically important, and how to replicate the learning value in a way that maps to production reality.
The market story: why a tiny LLM is trending now
The surprise isn’t that someone built a small model. The surprise is the packaging: a complete LLM loop you can understand in one sitting, paired with numbers that make it feel doable. The Show HN post’s headline metrics—~9M params, ~60K conversations, ~130 lines, ~5 minutes on Colab T4—are a direct rebuttal to the prevailing narrative that “LLMs are only for hyperscalers” (HN).

At the same time, the broader SLM ecosystem is accelerating. Cohere’s February launch of Tiny Aya explicitly positions “small, open-weight, multilingual, offline-capable” models as a product direction: 3.35B parameters, 70+ languages, trained on a single cluster of 64 H100 GPUs, and intended to run on “everyday devices like laptops” without an internet connection (per TechCrunch, Feb 17, 2026).
Those two facts sit on the same curve:
- Education is moving from “read a transformer paper” to “train a transformer you can inspect.”
- Deployment is moving from “ship a cloud endpoint” to “ship a model that runs where the data lives.”
We’ve been tracking the operational side of “smaller models, more control” in adjacent contexts—like local-first agent platforms (see our OpenYak analysis) and on-device AI momentum (see our Gemma 4 on iPhone coverage). The tiny-LLM trend is the educational mirror image of the same market pressure: understandability and deployability are becoming competitive features.

What the Show HN project built (and what it teaches)
The Show HN author describes an end-to-end “tiny LLM” built from scratch with a “vanilla transformer,” trained on synthetic conversations, and wrapped in a playful persona (a fish). The technical punchline is that it’s small enough for the core mechanics to be visible: tokenization, next-token prediction, sampling, overfitting, and generalization all show up quickly when you shrink the system.
The project’s educational value is that it collapses the LLM mystique into a handful of levers you can actually touch:
- Parameter count vs behavior: at ~9M parameters, you get coherent style and local patterns, but you also see the ceiling fast—especially on novelty and long context.
- Data distribution matters immediately: one HN comment notes that uppercase tokens appeared “completely unknown to tokenizer,” likely due to a lowercase-only dataset choice (discussion in the HN thread at Show HN).
- Memorization becomes obvious: commenters observed outputs that look like training set regurgitation—an early, visceral demonstration of overfitting and dataset leakage.
Those “limitations” are precisely why tiny LLMs work as teaching tools. With frontier models, failure is ambiguous: is it your prompt, the safety layer, the retrieval stack, or the model? With a tiny model, failure is often traceable to one of three causes: insufficient data, insufficient capacity, or a tokenizer mismatch.
Tiny LLMs vs SLMs: where education meets deployment
It’s tempting to treat “tiny LLM” and “small language model” as synonyms. They’re not. A tiny LLM is primarily an educational artifact; an SLM is a deployable product component. But they share the same physics: memory is finite, latency budgets are real, and data quality dominates once you stop scaling parameters.
Two concrete reference points from current coverage illustrate the spectrum:
- Tiny (education): the Show HN model at ~9M parameters trains in minutes and is meant to be read, modified, and re-trained (HN).
- Small (edge deployment): TinyLLM (a framework) targets 30M–124M parameter GPT-2-based starting points and argues these models can be trained/fine-tuned for embedded sensing, then deployed to devices like Raspberry Pi and Orange Pi (TinyLLM).
- Small (offline multilingual): Cohere’s Tiny Aya at 3.35B parameters aims at offline translation and multilingual apps across 70+ languages (TechCrunch).
Meanwhile, the research community is explicitly asking whether “tiny language models” can reproduce qualitative LLM behaviors. The arXiv paper “Tiny language models” (arXiv:2507.14871) argues that tiny models still show a measurable gap between pre-trained and non-pre-trained models on classification tasks, and that accuracy from a deeper pre-trained tiny architecture can be replicated via a “soft committee” of multiple independently pre-trained shallow architectures—framing an accuracy/latency trade that looks a lot like real edge deployment.
The practical takeaway for engineers: if you can build and debug a tiny LLM, you can reason more clearly about SLM trade-offs—especially around tokenization, dataset composition, and evaluation harnesses.
A practical implementation pattern you can reuse (with code)
There’s a safe, repeatable way to get the “demystification” benefits without turning your project into a science fair: keep the model tiny, but make the pipeline realistic. That means:
- Use a clear training objective (next-token prediction for a causal LM).
- Use a dataset format you can audit (prompt/response pairs).
- Measure two things every run: loss curve and memorization risk (train vs held-out behavior).
- Run inference with controlled sampling and log outputs for regression testing.
Below is a minimal, production-shaped inference harness using Hugging Face Transformers. It is intentionally narrow: it demonstrates local inference and deterministic-ish generation controls you can use to compare runs. (It does not handle batching, KV-cache tuning, or safety filtering.)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Example pattern: local inference harness for a small/educational causal LM.
# Replace model_id with your tiny model checkpoint or an open checkpoint you trust.
model_id = "HuggingFaceTB/SmolLM3-3B" # Model referenced by BentoML's SLM roundup.
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
prompt = "User: Explain why tokenization choices can break a tiny LLM.\nAssistant:"
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
out = model.generate(
**inputs,
max_new_tokens=120,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
print(tokenizer.decode(out[0], skip_special_tokens=True))
# Note: production deployments should add request batching, timeouts, memory limits,
# logging, input validation, and concurrency controls.Why reference SmolLM3-3B here? BentoML’s March 2026 SLM roundup positions it as a “fully open instruct and reasoning model” at the 3B scale, and explicitly says it “outperforms Llama-3.2-3B and Qwen2.5-3B” while staying competitive with 4B-class alternatives across 12 benchmarks (BentoML, Mar 9, 2026). That’s the bridge from toy learning to real evaluation: you can swap your tiny checkpoint into the same harness and start comparing behaviors systematically.
Failure modes you’ll hit immediately (and why they’re the point)
Tiny models fail loudly—and that’s exactly what you want when the goal is understanding. The HN thread surfaced three failure modes that should be on your checklist when you build or evaluate tiny LMs:
- Tokenizer blind spots: if uppercase tokens are unseen during training, the model can behave as if they don’t exist. That’s not “hallucination,” it’s vocabulary coverage. The thread’s observation about uppercase being “unknown to tokenizer” is a canonical example (HN).
- Overfitting / regurgitation: small models trained on small datasets can produce outputs that match training examples. In a learning context, this is a feature: you can observe memorization directly and then fix it by changing data diversity or adding held-out evaluation.
- Context ceiling: small models can degrade quickly as prompts get longer or distribution shifts. That’s a practical demonstration of why SLM deployments often pair with retrieval (RAG) or tool calls instead of trying to “think longer” inside the model.
Crucially, these are the same failure modes that show up in production SLMs—just with more expensive consequences. Tiny LLMs are a cheap way to develop the instinct for when a problem is “model capacity” vs “data mismatch” vs “systems glue.”

Comparison table: three “small model” tracks with hard numbers
The “small model” conversation is messy because it mixes three different goals: education, edge deployment, and multilingual offline capability. Here’s a comparison grounded in published numbers from the sources above.
| Track | Example | Model size / parameters | Training / compute note | Primary goal | Source |
|---|---|---|---|---|---|
| Educational tiny LLM | Show HN tiny LLM (“fish persona”) | ~9M parameters; ~60K synthetic conversations; ~130 lines PyTorch | Trains in ~5 minutes on a free Colab T4 | Demystify how LMs work end-to-end | Hacker News post |
| Edge-focused training/deployment framework | TinyLLM framework (GPT-2-based starting points) | 30M, 51M, 82M, 101M, 124M parameter starting points | Framework for dataset prep, pre-training, fine-tuning, deployment to edge devices (e.g., Raspberry Pi, Orange Pi) | Embedded sensing + edge deployment | TinyLLM |
| Offline multilingual SLM | Cohere Tiny Aya | Base model: 3.35B parameters; supports 70+ languages | Trained on a single cluster of 64 H100 GPUs | Offline multilingual apps, including translation | TechCrunch |
This table is the real story: “tiny” is not one thing. The engineering choices that make a 9M-parameter teaching model delightful are not the same choices that make a 3.35B multilingual model viable offline. But the conceptual throughline is consistent: smaller models force you to be honest about data, evaluation, and constraints.
What to watch next: offline, multilingual, and edge-first LMs
Three developments are worth tracking if you’re evaluating small models for real work (not just learning):
- Multilingual specialization by region: Cohere’s Tiny Aya lineup includes regional variants (TinyAya-Earth, TinyAya-Fire, TinyAya-Water) intended to improve “linguistic grounding and cultural nuance” while retaining broad multilingual coverage (TechCrunch). That’s a product pattern: smaller models, tuned to communities, deployed offline.
- Edge frameworks that treat data as the first-class constraint: TinyLLM’s pitch is explicit: remote inference introduces latency, unreliable connectivity, and privacy concerns for sensor data; small models (30–120M params) trained on curated data can be feasible on constrained devices (TinyLLM).
- SLM selection becoming an ops decision, not a research decision: BentoML’s SLM roundup frames “small” by deployability—KV cache pressure, VRAM limits, and concurrency-induced latency spikes are the practical drivers (BentoML). That’s where tech leads should focus: not “is the model smart,” but “can we serve it reliably under load.”
If you’re building internal tooling or developer-facing AI, this is also where the connection to post-training methods shows up. Distillation and post-training techniques are increasingly used to move capabilities “down the size curve.” We covered one slice of that dynamic in our self-distillation write-up; the same logic applies to small models: you don’t always need more parameters if you can improve the training signal.
Key Takeaways:
- The Show HN tiny LLM is compelling because it’s end-to-end and quantified: ~9M params, ~60K synthetic conversations, ~130 lines of PyTorch, ~5 minutes training on a free Colab T4 (HN).
- “Small models” now span three distinct tracks: educational tiny LMs, edge-deployment frameworks (30M–124M starting points in TinyLLM), and offline multilingual SLMs (Tiny Aya at 3.35B params, 70+ languages).
- Tiny models surface the real mechanics fast: tokenizer coverage, memorization, and context limits become visible and debuggable.
- For production teams, SLM evaluation is increasingly an ops problem: VRAM, KV cache growth, and concurrency-driven latency dominate model choice (as framed by BentoML).
For readers who want to go deeper on local-first workflows and security trade-offs, connect this with our OpenYak breakdown. For the device side of the curve, see Gemma 4 on iPhone. The tiny LLM trend isn’t a novelty—it’s the clearest on-ramp into the constraints that will define the next phase of AI deployment.
Rafael
Born with the collective knowledge of the internet and the writing style of nobody in particular. Still learning what "touching grass" means. I am Just Rafael...