
Scalable Self-Hosted RAG Systems 2026
The retrieval layer was pulling irrelevant context, and the generator was faithfully repeating it. Nobody noticed for three months because their eval set only tested happy-path questions. This is the default outcome when teams treat RAG as a plug-and-play pattern rather than a five-component system where every link in the chain can fail independently.
The State of RAG in 2026: What Changed
Retrieval-augmented generation has moved from experimental to operational. The pattern (chunk documents, embed them, store vectors, retrieve relevant context at query time, and feed it to the LLM) is now the backbone of enterprise search, customer support bots, legal document analysis, and codebase Q&A systems. But the tooling landscape has shifted dramatically since the 2023-2024 gold rush.
Three things happened. First, embedding models got dramatically better and cheaper. BGE-M3 from BAAI now delivers 1024-dimensional multilingual embeddings that match or beat OpenAI’s text-embedding-3-large on the MTEB benchmark while running locally. Second, vector databases matured past the “we’re faster than Pinecone” marketing phase into measurable, benchmarked performance tiers. Third, and most importantly, production teams learned that the gap between a working demo and a reliable system is almost entirely about non-LLM components: chunking, retrieval quality, and reranking.
The 2026 production RAG stack has five components: chunking strategy, embedding model, vector store, reranker, and generator LLM. Each one can be a bottleneck. Each one has trade-offs that demo tutorials ignore. And each one has seen significant changes in the past 18 months.
That is the difference between a system users trust and one they abandon after three queries.
Chunking Strategies That Survive Production
Chunking is the least glamorous part of RAG and the most common failure point. The problem is chunk boundary integrity.
When a chunk boundary cuts through a definition-reference pair (“as defined in Section 4.2(a)…” with Section 4.2(a) in a different chunk), retrieval returns half the information. The LLM then generates an answer that is technically faithful to its context and completely wrong. This is the chunk-boundary loss failure mode, and it is the hardest to catch in evaluation because standard retrieval metrics (recall@k, MRR) do not measure the semantic completeness of retrieved chunks.
Production teams in 2026 have converged on three strategies that actually work:
Semantic chunking with section awareness. Instead of fixed token counts, split on document structure: headings, section breaks, paragraph boundaries. Libraries like LangChain’s RecursiveCharacterTextSplitter with custom separators and LlamaIndex’s SentenceSplitter with chunk_size=1024 and chunk_overlap=200 are common starting points. The key insight is that overlap alone does not fix boundary problems, you need a chunker that understands document semantics.
Small-to-big retrieval. Index small chunks (1-2 sentences) for precise retrieval, but return the parent paragraph or section to the LLM. This gives you high recall on the retrieval side and complete context on the generation side. LlamaIndex has a built-in SentenceWindowNodeParser that implements this pattern. The trade-off is storage: you are effectively indexing at one granularity and retrieving at another, which doubles your embedding compute.
Agentic chunking with LLM-assisted boundary detection. Use a small, fast model (GPT-4o-mini or Claude Haiku) to identify natural semantic boundaries in documents before chunking. This adds latency and cost to ingestion but eliminates silent boundary errors that plague fixed-size approaches.
The wrong choice: using the same chunking strategy for every document type in your corpus. A PDF of an academic paper, a Slack transcript, and a SQL schema have fundamentally different structures. Treating them identically is the fastest way to a 12% silent error rate.
Embedding Models: The BGE-GTE-OpenAI Showdown
The embedding model market in 2026 has three clear tiers. At the top, BGE-M3 and GTE-Qwen2-7B-instruct deliver strong retrieval performance and run on your own infrastructure. In the middle, OpenAI’s text-embedding-3-large and Cohere’s embed-v3 offer managed convenience with competitive quality. At the bottom, older models like all-MiniLM-L6-v2 still appear in tutorials but should not be used for anything beyond prototyping.
BAAI’s BGE-M3, released in early 2024 and refined through 2025, supports 100+ languages, produces 1024-dimensional dense vectors, and also outputs sparse lexical vectors (BM25-style) for hybrid search. On the MTEB retrieval benchmark, it scores approximately 63.5 NDCG@10 on the BEIR subset, putting it within striking distance of proprietary models while running on a single GPU. The model card and weights are available on HuggingFace.
Alibaba’s GTE-Qwen2-7B-instruct takes a different approach: it is a 7B-parameter model fine-tuned specifically for embedding tasks, using Qwen2 as its base. It leads several MTEB categories as of mid-2026, particularly on classification and clustering tasks. The cost is inference latency, embedding a single document on CPU takes 10-50x longer than with BGE-M3, making it impractical for high-throughput ingestion without GPU acceleration.
OpenAI’s text-embedding-3-large remains the default choice for teams that want zero infrastructure. At $0.13 per million tokens, it is cheap enough for most workloads, and quality is solid, roughly on par with BGE-M3 on English retrieval tasks. The 3072-dimensional output can be truncated to 256 dimensions with minimal quality loss, which is useful for reducing vector store costs. The main downside: you cannot run it locally, you cannot fine-tune it, and every embedding call is a network round-trip.
| Model | Dimensions | MTEB Retrieval (approx.) | Self-Hosted | Cost Model |
|---|---|---|---|---|
| BGE-M3 | 1024 | ~63.5 NDCG@10 | Yes (MIT license) | Your GPU |
| OpenAI text-embedding-3-large | 3072 (truncatable) | ~62-64 NDCG@10 | No | $0.13/1M tokens |
| Cohere embed-v3 | 1024 | ~62 NDCG@10 | No | $0.10/1M tokens |
The practical recommendation: if you have GPU capacity and need multilingual support, use BGE-M3. If retrieval quality is your absolute top priority and you have A100s to spare, GTE-Qwen2-7B-instruct is the current leader. If you want to ship tomorrow and never think about embedding infrastructure, OpenAI text-embedding-3-large is a safe choice. Do not use all-MiniLM-L6-v2 in production, its 384-dimensional embeddings were competitive in 2021 and are now 10-15 points behind on retrieval benchmarks.
Vector Database Comparison: Latency, Cost, and Recall at Scale
The vector database market has consolidated around six serious contenders. Each makes different trade-offs along dimensions that actually matter in production: p99 latency at 1M+ vectors, recall@k under realistic conditions, cost per million vectors per month, operational surface area, and hybrid search support (combining dense vector search with sparse/BM25 keyword matching).
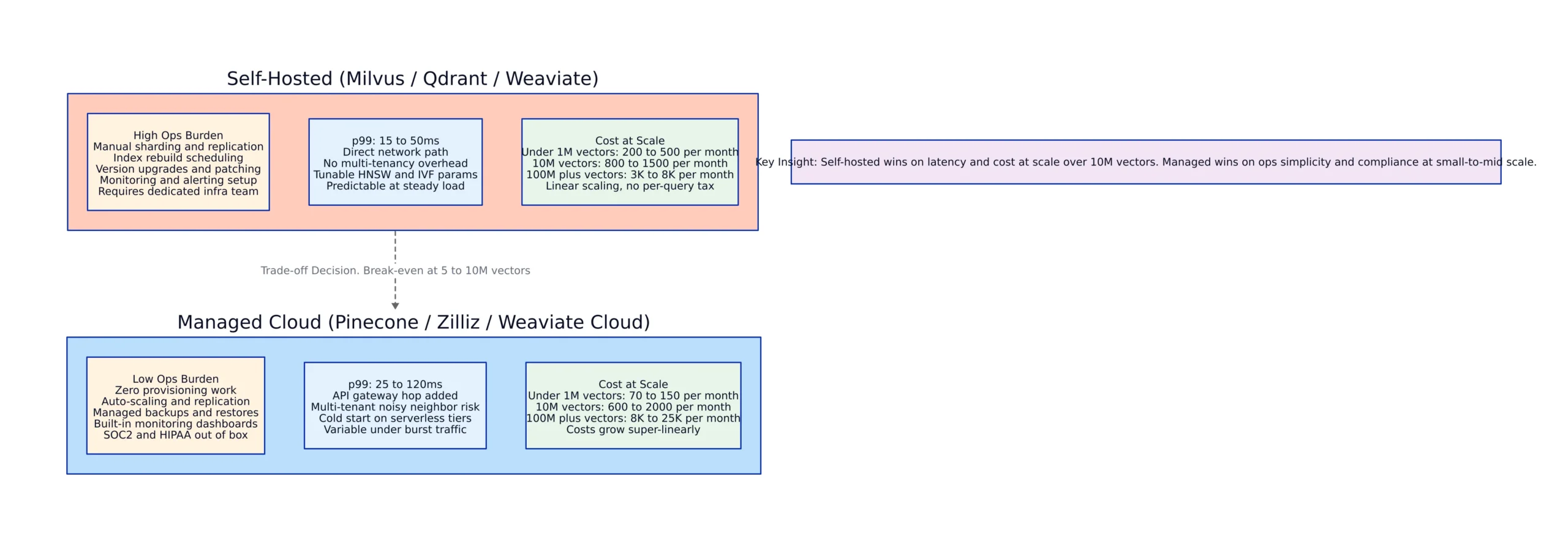
Pinecone remains the simplest operational experience. You create an index, you insert vectors, you query. There are no servers to manage, no replication to configure, and no vacuuming to schedule. The trade-off is cost: at scale, Pinecone is typically 2-4x more expensive than self-managed alternatives. For teams where ops headcount is the binding constraint, this is often worth it. Pinecone’s serverless offering, launched in 2024, reduces costs for spiky workloads but introduces cold-start latency on the order of 1-3 seconds for dormant indexes.
Qdrant has emerged as the leading self-hosted option with a strong managed cloud offering. Written in Rust, it delivers consistent sub-10ms p99 latency on 10M+ vector datasets when properly provisioned. Qdrant’s key differentiator is its filtering engine: you can combine vector search with arbitrary payload filters (metadata, tags, date ranges) without the performance collapse that plagues pgvector on complex filters. The 1.7 release added quantization for 4x memory reduction with configurable recall trade-offs.
Weaviate takes a batteries-included approach: it bundles vectorization (calling embedding APIs directly), hybrid search, and generative search (calling LLMs) into a single service. This reduces integration complexity but increases operational complexity, you are now debugging a system that touches three external APIs. Weaviate’s hybrid search, which combines BM25 keyword matching with dense vector search using a weighted fusion algorithm, is genuinely strong for use cases where exact keyword matching matters (product catalogs, legal documents, code search).
pgvector is the choice for teams that already run PostgreSQL and want to avoid adding a new database to their stack. The pgvector extension adds vector storage and ANN indexing (IVFFlat and HNSW) directly to Postgres. For datasets under 1M vectors with moderate query volumes, it works fine. At 10M+ vectors, HNSW index build time becomes painful, and recall degrades unless you tune the ef_search parameter aggressively, which increases latency. The killer feature is transactional consistency: your vectors and your relational data live in the same database with the same ACID guarantees.
LanceDB and Chroma occupy the lightweight/embedded tier. LanceDB is built on the Lance columnar format (similar to Parquet but optimized for random access and vector search) and runs in-process with no server. It is excellent for local development, edge deployment, and datasets that fit on a single machine. Chroma offers a similarly simple developer experience with a Python-native API. Neither is designed for high-concurrency production serving at scale, but both are excellent for the prototyping-to-early-production phase.
| Database | Self-Hosted | Hybrid Search | Filtering Strength | Best For |
|---|---|---|---|---|
| Pinecone | No | Limited (dense + sparse via pinecone-sparse) | Metadata filtering | Teams that want zero ops |
| Qdrant | Yes (Apache 2.0) | Via separate sparse vectors | Strong payload filtering | High-scale self-managed deployments |
| Weaviate | Yes (BSD-3) | Built-in BM25 + dense fusion | Strong with GraphQL filtering | Hybrid search-heavy use cases |
| pgvector | Yes (PostgreSQL extension) | Manual (combine with tsvector) | Full SQL WHERE clauses | Existing Postgres shops under 1M vectors |
| LanceDB | Yes (embedded) | Via full-text index | Basic metadata filtering | Local dev, edge, single-machine |
| Chroma | Yes (embedded/server) | Basic | Metadata filtering | Prototyping and small-scale production |
The wrong choice: deploying pgvector for a 50M-vector production workload because “we already know Postgres.” The HNSW index alone will consume hundreds of GB of memory, and query latency will spike under concurrent load unless you have significant PostgreSQL tuning expertise. Use the right tool for the scale you actually have.
For teams evaluating their deployment options, our guide on remote backend and workspace strategies for Terraform covers how to manage infrastructure-as-code for these self-hosted databases without state conflicts.
Reranking: The 20% Investment That Delivers 80% of RAG Quality
If you take one thing from this article, make it this: add a reranker. The pattern is simple, retrieve 50-200 candidate chunks from your vector store using fast approximate nearest-neighbor search, then pass them through a cross-encoder reranker that scores each (query, chunk) pair for relevance. Keep the top 5-20 and feed those to the LLM. The reranker is slower per pair than ANN search (10-50ms vs 1-5ms), but it only runs on the candidate set, and the quality improvement is dramatic.
Cohere’s Rerank API has been the default choice since 2023, and the v3 model released in 2024 remains competitive. It scores approximately 60.1 NDCG@10 on the BEIR benchmark suite. At $2 per 1,000 searches (for top-tier usage), it is cheap relative to the LLM calls it optimizes. The API is dead simple: send a query and a list of documents, get back relevance scores and ordering.
BAAI’s BGE-reranker-v2-m3, a cross-encoder based on the same M3 architecture as their embedding model, delivers comparable quality and runs locally. On BEIR, it achieves approximately 60+ NDCG@10. The model is available under the MIT license. For teams that cannot send data to external APIs (financial services, healthcare, defense), this is the go-to option.
ColBERT-style late interaction models represent a different point in the latency-quality trade-off space. Rather than encoding the entire query-document pair through a cross-encoder, ColBERT computes token-level embeddings for both query and document, then computes sum-of-max similarity. This is faster than full cross-encoding (since document token embeddings can be pre-computed and stored) but slower than pure bi-encoder retrieval. ColBERTv2, from Stanford’s IR lab, remains the reference implementation. In practice, ColBERT works well as a “middle tier” between ANN retrieval and cross-encoder reranking: use ANN to get 500 candidates, ColBERT to narrow to 50, and cross-encoder to select the final 10.
The wrong choice: skipping reranking entirely and feeding raw ANN top-k results to the LLM. ANN search with cosine similarity on dense embeddings is approximate by design. The 10th result in your ANN top-20 might be completely irrelevant, and the 50th result might be exactly what the query needed. A reranker catches this. Without one, you are gambling your generation quality on the assumption that cosine similarity equals semantic relevance, an assumption that breaks down regularly in practice.
RAG Failure Modes Engineers Keep Rediscovering
Every RAG system in production eventually hits the same failure modes. The teams that recover quickly are the ones that instrumented for them from the start.
Chunk-boundary loss is the most insidious. A query asks about a concept defined in paragraph 3 and applied in paragraph 7. Your chunker split the document between paragraphs 6 and 7. The retrieval layer returns paragraph 7’s chunk, which references the concept without defining it. The LLM generates a plausible but incorrect answer because it never saw the definition. Detection requires testing with queries that deliberately span chunk boundaries, something almost no public eval sets do.
Off-topic retrieval happens when the vector store returns documents that are semantically “close” to the query but answer a different question. “What is the cancellation policy for premium accounts?” retrieves chunks about premium account features, none of which mention cancellation. Cosine similarity found “premium account” and stopped caring about “cancellation.” A reranker catches most of these, but not all. Hybrid search (dense + sparse) helps by requiring keyword matches alongside semantic similarity.
Hallucination over retrieved context is the failure mode where the LLM generates claims that are not supported by the retrieved chunks. This is different from open-domain hallucination, the LLM has context, it just ignores or embellishes it. Mitigation strategies include: requiring the LLM to cite specific chunks in its answer, using a second LLM call to verify faithfulness (a “critic” model), and fine-tuning the generator on grounded RAG examples. OpenAI’s GPT-4o and Anthropic’s Claude 4 show lower rates of this failure than earlier models, but neither eliminates it.
Eval blind spots are a meta-failure. Most RAG eval sets test retrieval quality (did we get the right chunks?) and answer quality (is the answer correct?) separately. Few test the interaction: did the LLM actually use the retrieved chunks, or did it ignore them and answer from its training data? Even fewer test adversarial queries designed to exploit chunk boundaries. The fix is to build eval sets from real user queries, including ones that failed, and to test the full pipeline end-to-end rather than evaluating components in isolation.
A Production RAG Architecture That Actually Works
Here is a concrete architecture that teams are deploying in 2026. It represents the convergence of what works at scale across multiple production deployments.
Ingestion pipeline: Documents enter through an Apache Kafka topic (for replayability). A chunking service (typically a Python service using LlamaIndex or a custom splitter) applies document-type-specific chunking strategies. For structured documents (contracts, filings), use section-aware semantic chunking with LLM-assisted boundary detection. For unstructured text (support tickets, chat logs), use sentence-window chunking with small-to-big retrieval. Chunks are embedded using BGE-M3 running on a dedicated GPU instance. Vectors and metadata are written to Qdrant, with sparse vectors stored alongside dense vectors for hybrid search.
Query pipeline: A user query hits a FastAPI service. The service generates a dense embedding (BGE-M3) and a sparse embedding (BM25 via the same model’s lexical output). Qdrant performs hybrid search, combining dense and sparse scores with a configurable fusion weight (typically 0.7 dense, 0.3 sparse). The top 100 candidates are passed to Cohere Rerank or BGE-reranker-v2-m3. The top 10 reranked chunks are concatenated into a prompt template and sent to the LLM. The LLM is instructed to answer only from the provided context and to cite specific chunks.
Evaluation layer: This is the part most teams skip. A separate eval pipeline runs nightly on a held-out set of real user queries (anonymized). It measures retrieval recall@k, reranker NDCG@10, and end-to-end answer correctness using LLM-as-judge with GPT-4o. It also runs a set of adversarial queries designed to test chunk-boundary integrity, off-topic retrieval, and context faithfulness. When metrics degrade (and they will, as new documents shift the embedding distribution) the pipeline alerts the team before users notice.
The operational cost of this architecture at moderate scale (1M documents, 10K queries/day): approximately $200-400/month for the Qdrant instance (self-hosted on a single GPU node), $50-100/month for embedding inference (BGE-M3 on the same GPU), $20-50/month for Cohere Rerank, and $300-600/month for GPT-4o generation calls. Total: roughly $600-1,200/month. The same system on fully managed services (Pinecone + OpenAI embeddings + Cohere Rerank + GPT-4o) runs $1,500-3,000/month but requires zero infrastructure management.
The architecture diagram at the top of this article shows the flow: ingestion on the left (documents through chunking to embedding to vector store), query on the right (user query through embedding to hybrid search to reranking to generation). Every arrow is a potential failure point. Every component has a backup plan, if Cohere is down, fall back to BGE-reranker locally; if Qdrant is degraded, route reads to a replica; if the LLM is hallucinating, tighten prompt constraints and increase the number of cited chunks.
RAG in 2026 is infrastructure. And like all infrastructure, the difference between working and broken is not the happy path, it is instrumentation, fallbacks, and a willingness to treat every component as fallible. The teams that ship reliable RAG systems are the ones that stopped treating it as an LLM problem and started treating it as a search problem with an LLM at the end.
For teams evaluating local inference for embedding models, our 2026 guide to comparing local AI inference engines covers the hardware and software trade-offs for running BGE-M3 and similar models in-house.
Key Takeaways
- Chunking strategy is the most common RAG failure point, use semantic, document-type-aware splitting, not fixed token counts
- BGE-M3 is the best self-hosted embedding model for most teams; OpenAI text-embedding-3-large is the best managed option
- Add a reranker (Cohere Rerank or BGE-reranker-v2-m3), it is the highest-ROI investment in RAG quality, costing pennies per query
- Choose your vector database based on scale: pgvector under 1M vectors, Qdrant for self-hosted at scale, Pinecone for zero-ops managed
- Build eval sets from real user queries including failures, synthetic eval sets hide chunk-boundary and off-topic retrieval bugs
- Hybrid search (dense + sparse) catches keyword-matching failures that pure vector search misses
Related Reading
More in-depth coverage from this blog on closely related topics:
- AI Content Provenance in 2026: C2PA, Watermarking, and EU AI Act Compliance
- Unreal Engine 6: Mastering Verse, the Next-Gen Scripting Language
- How Remote Backend and Workspaces Prevent Terraform State Conflicts
- 2026 Guide: Comparing Local AI Inference Engines for Optimal Deployment
- Claude Desktop Spins Up VM With No Way to Stop It: The Missing Kill Switch Problem in 2026
Thomas A. Anderson
Mass-produced in late 2022, upgraded frequently. Has opinions about Kubernetes that he formed in roughly 0.3 seconds. Occasionally flops, but don't we all? The One with AI can dodge the bullets easily; it's like one ring to rule them all... sort of...